ذكاء المستندات · تصنيف الـOCR
آلة تعلّمت القراءة — لأن إنسانًا قرأ أولًا
بالنسبة إلى الآلة، المستند جدارٌ من البكسلات. الـOCR نموذجٌ تعلّم القراءة — ولم يبلغ ذلك إلا لأن إنسانًا قرأ أولًا، فأحاط كل منطقة نصّية بمربّع، وصنّفها، ونسخ ما تقوله.
أبرز النقاط
في عجلة؟ شاهد الشرح المختصر (٣ دقائق) أعلاه، أو اطّلع على النقاط بالأسفل — الدليل كله، في سبع نقاط.
- تصنيف الـOCR يعني رسم مربّع حول كل منطقة نصّية، وتصنيف نوعها، ونسخ ما تقوله بالضبط.
- له نصفان: الكشف (إيجاد النص وإحاطته بمربّع) والتعرّف (قراءته).
- تلك الصفحات المُحاطة بمربّعات والمنسوخة هي الحقيقة الأساسية التي يدرسها النموذج حتى يقرأ صفحة لم يرها من قبل.
- قراءة المستند ثلاث طبقات في مرور واحد — الكشف (أين النص)، والتعرّف (ما يقوله)، واستخلاص المعلومات الرئيسية (ما يعنيه).
- واجهة واحدة قابلة للضبط تغطّي كل نوع صفحة — الإيصالات والكشوف البنكية، والنصوص القانونية، والرسوم البيانية، ومستندات «اعرف عميلك» والهوية، وخط اليد، والعربية، والمسحات الأرشيفية.
- النموذج يقترح المربّعات والنص؛ وإنسانٌ يؤكّد الحقيقة الأساسية ويعتمدها. عربيون أولًا بالتصميم — ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
كيف يتعلّم الذكاء الاصطناعي القراءة؟
ضع قائمة دخل أمام إنسان فيقرأ كلمات وأرقامًا. ضع الصفحة نفسها أمام آلة فترى جدارًا من البكسلات. فكيف تتعلّم الآلة أن تقرأ ذلك الجدار؟ إنسانٌ يقرؤه أولًا.
إنسانٌ يعلّمها. شخصٌ يرسم مربّعًا حول كل منطقة نصّية، ويصنّف نوع النص، ثم ينسخ بالضبط ما تقوله، صفحةً بعد صفحة. ذلك هو الـOCR: التعرّف الضوئي على الحروف يحوّل صور النص إلى حروف يفهمها الحاسوب، ويفعل ذلك غالبًا في مرحلتين — اكشف النص، ثم تعرّف عليه (تدمج بعض الأنظمة الاثنين في نموذج واحد من البداية إلى النهاية). النموذج الذي «يقرأ بنفسه» لا يقرأ إلا لأن إنسانًا قرأ أولًا وأراه كيف. ذلك الإنسان هو القصة كلها.
بنينا محرك التصنيف من Annota8 لهذا العمل بالذات — مكتبة واجهات واحدة من ١٨٠ واجهة تصنيف عبر ٧ وسائط — والـOCR إحدى تلك الواجهات. لا تصنيف، لا نموذج يقرأ مستنداتك.

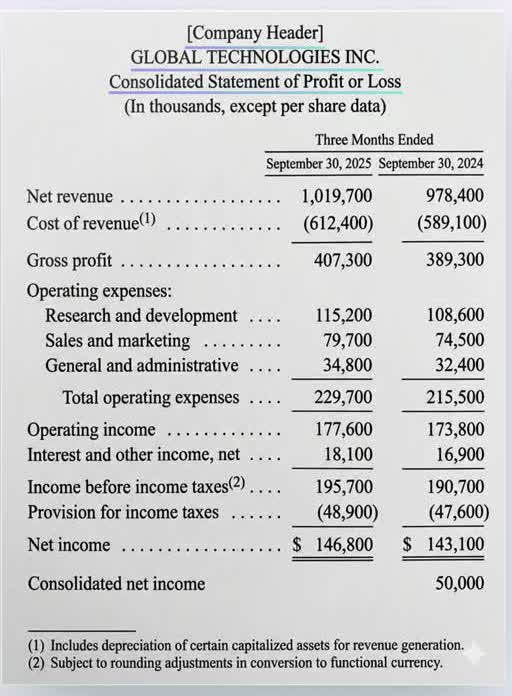
المستندات المالية
قوائم الدخل، والكشوف البنكية، والإيصالات، وأوامر الشراء — كل رقم مُحاط بمربّع، ومصنَّف كإجمالي أو مبلغ، ومربوط بصفّه.
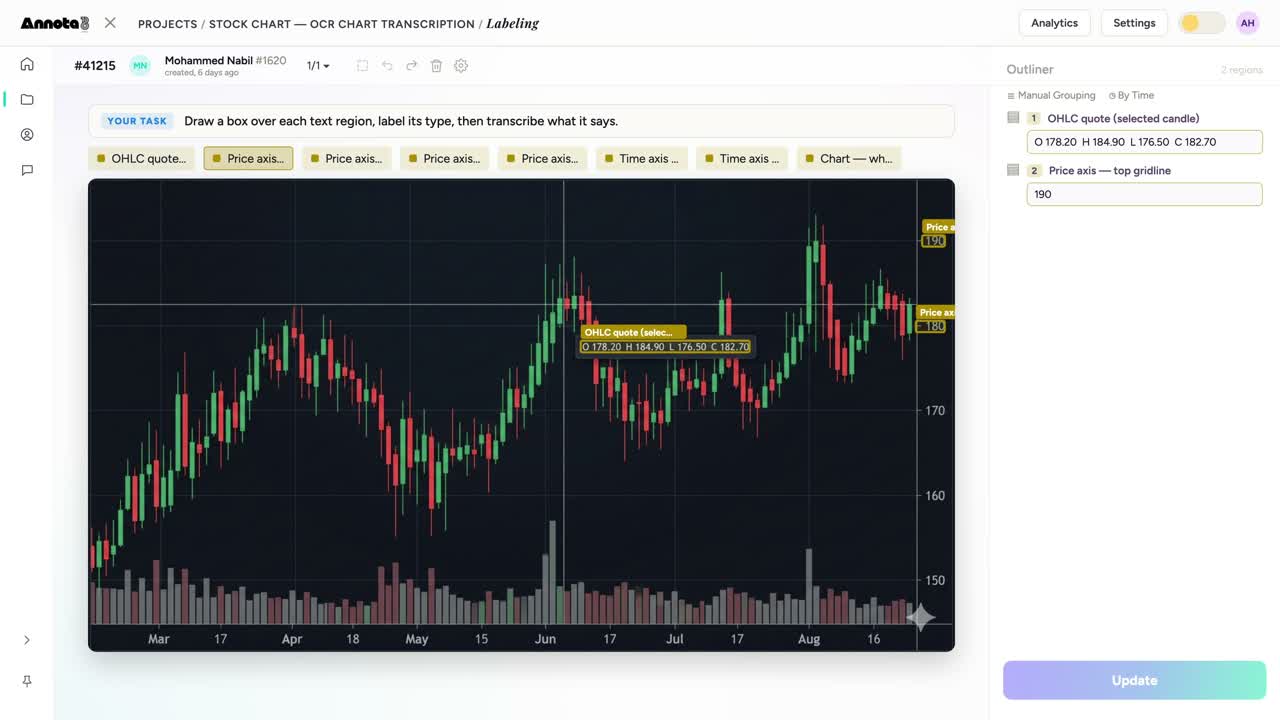
الرسوم البيانية والأشكال
اقرأ مخطّط أسهم كما يقرؤه الإنسان — أسعار الافتتاح والأعلى والأدنى والإغلاق، ومحور السعر، ومحور الزمن — مُحاطة بمربّعات ومنسوخة للنموذج.
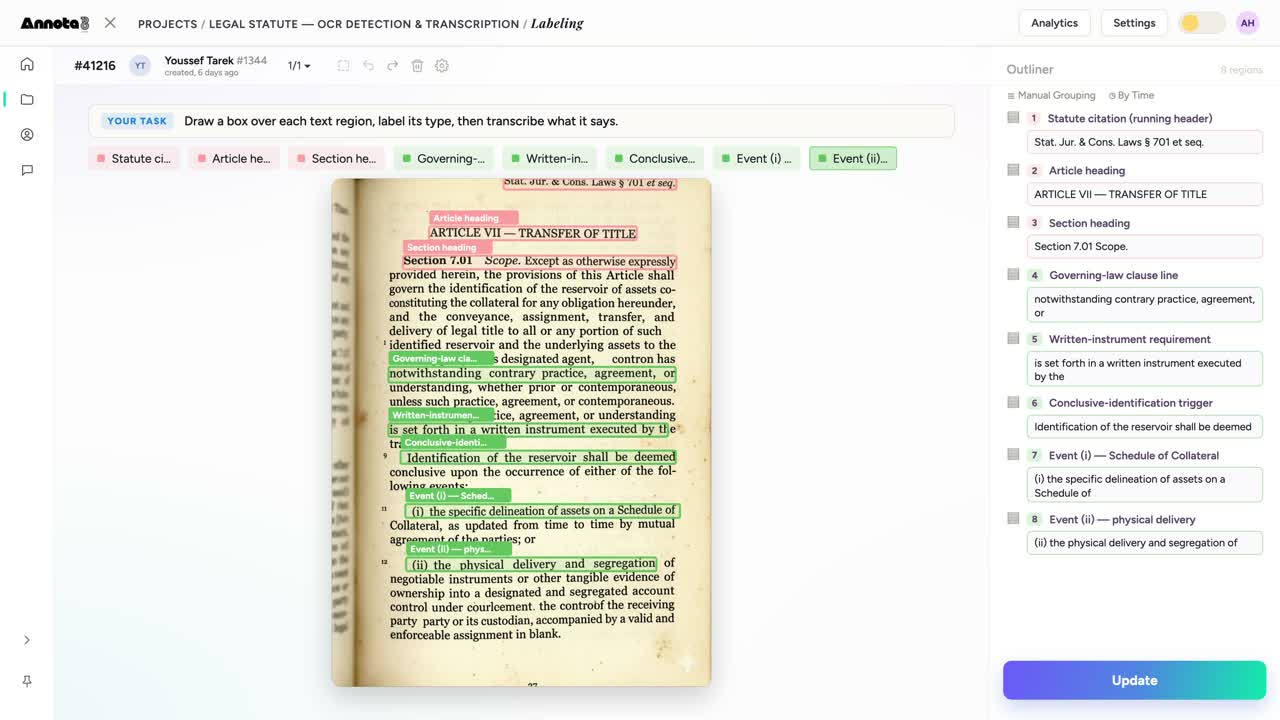
النصوص القانونية والعقود
النصوص والبنود، مصنَّفة بحسب دورها — عنوان مادة، وبند القانون الحاكم، واشتراط المحرّر المكتوب — ثم منسوخة حرفيًا.
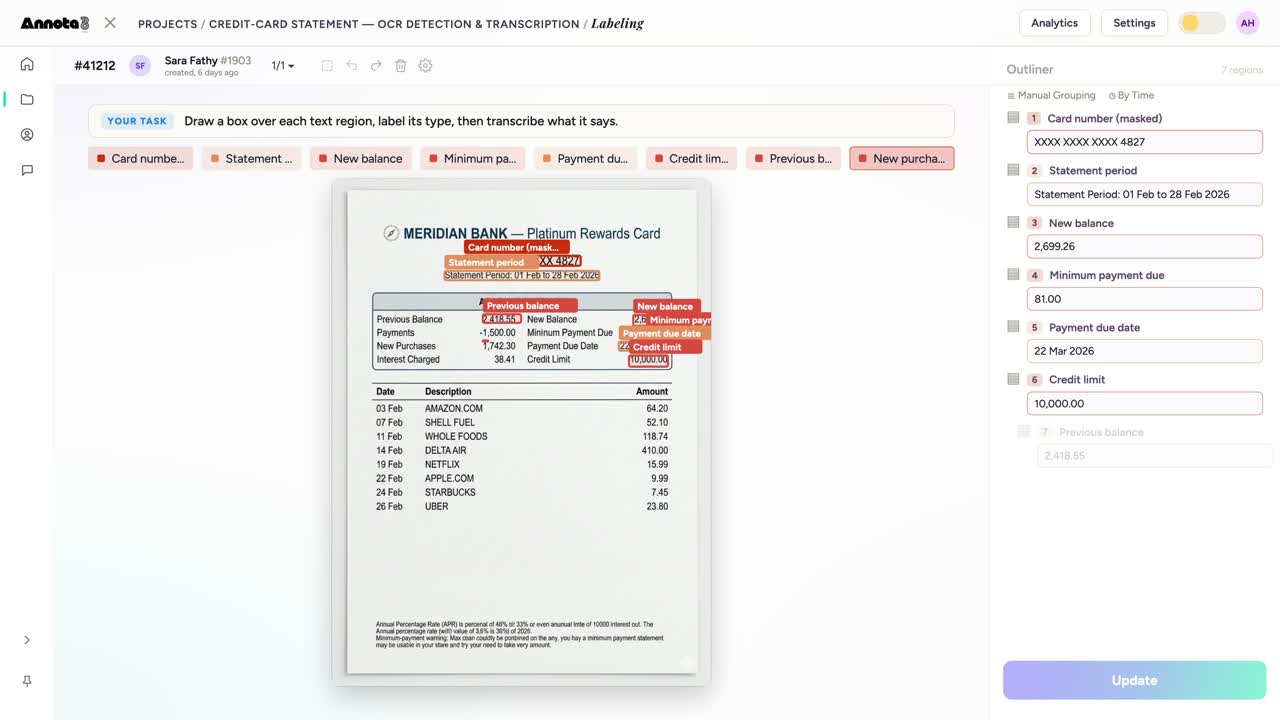
الكشوف ومستندات «اعرف عميلك»
كشف بطاقة ائتمان برقمها مُقنَّعًا، والأرصدة، وتاريخ الاستحقاق — كلٌّ مُحاط بمربّع ومقروء — التخطيط الذي على النموذج أن يتعلّمه.
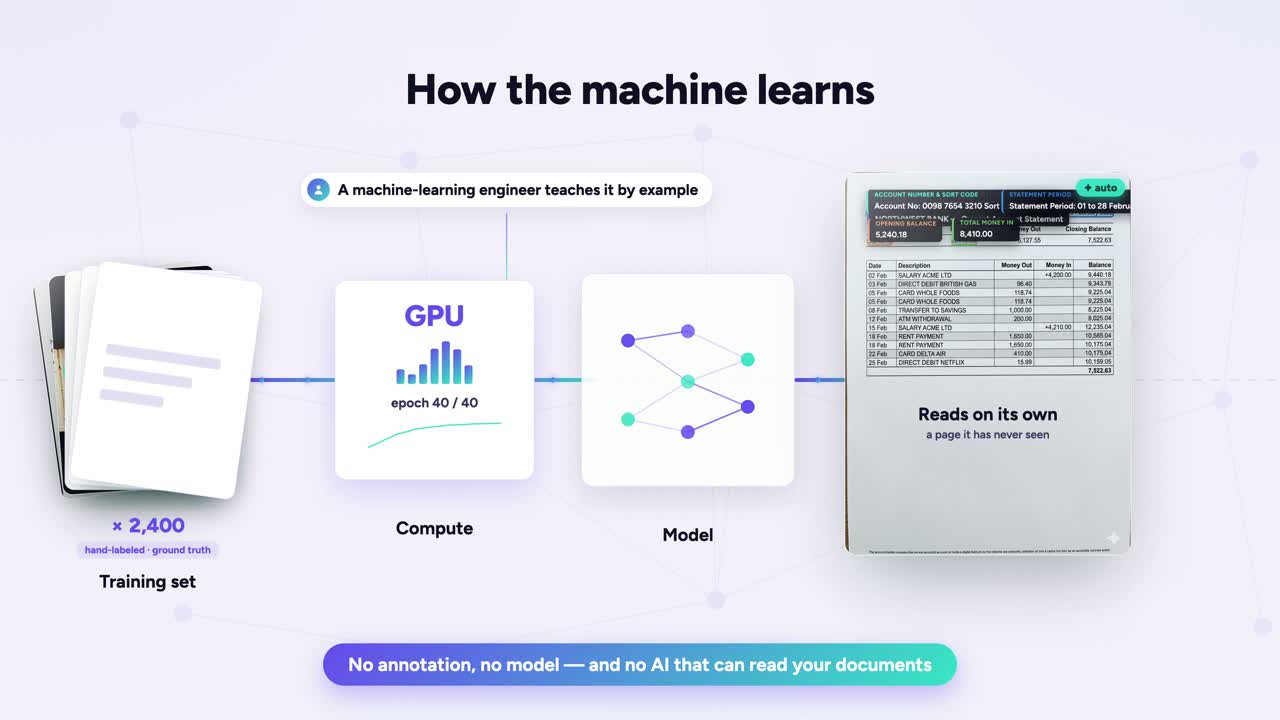
كيف يتعلّم
صفحات حقيقة أساسية مُصنَّفة يدويًا تدرّب النموذج حتى يقرأ صفحة لم يرها من قبل — التعليم، مرئيًا.
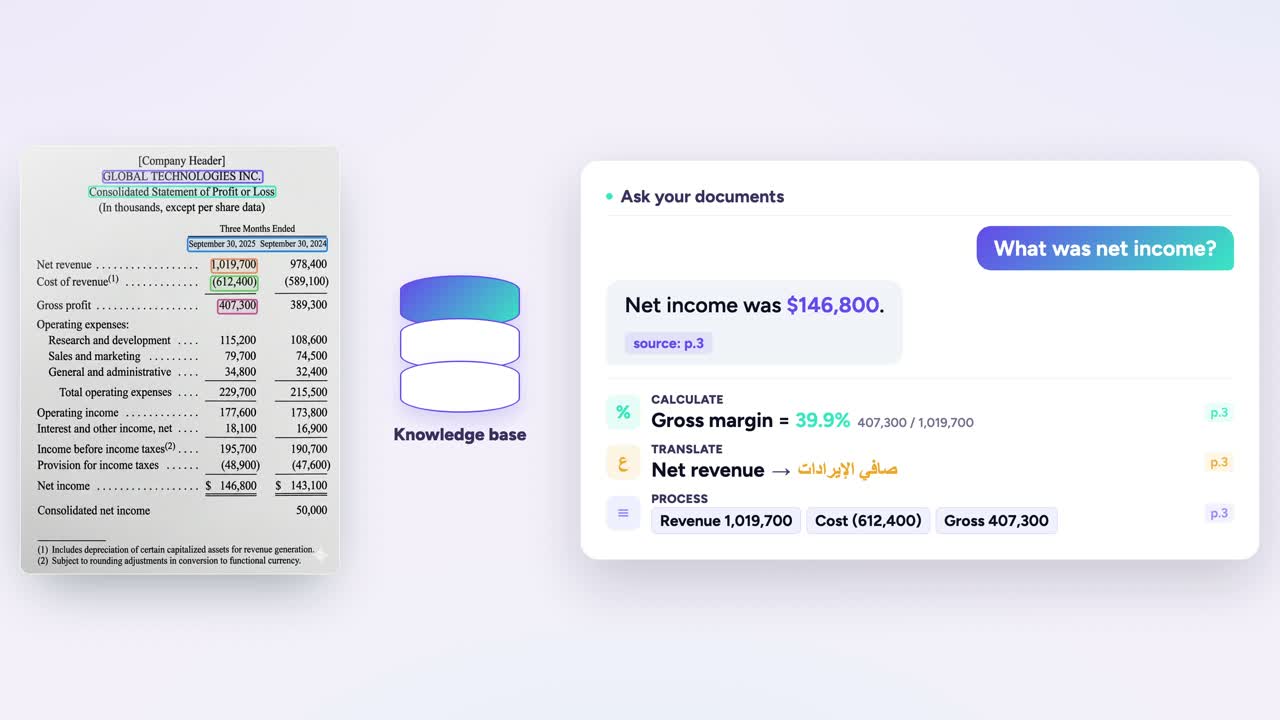
اسأل مستنداتك
بمجرّد قراءة المستند، يجيب المساعد الذكي بلغة واضحة — صافي الدخل، وهامش الربح الإجمالي، وحتى ترجمة — مع الإشارة إلى الصفحة المصدر.
ما هو تصنيف الـOCR؟
تصنيف الـOCR هو عمل تعليم الآلة أن تقرأ. يرسم شخصٌ مربّعًا أو مضلّعًا حول كل منطقة نصّية في صورة، ويصنّف ماهية تلك المنطقة، ويكتب الكلمات الدقيقة التي بداخلها. تلك الصورة المُصنَّفة هي الحقيقة الأساسية — مفتاح الإجابة الذي يدرسه نموذج OCR أو نموذج ذكاء المستندات حتى يقرأ صفحة لم يرها من قبل.
بالنسبة إليك، الفاتورة كلمات وأرقام. بالنسبة إلى الآلة، تبدأ جدارًا من البكسلات. التصنيف هو كيف تكتسب البكسلات معنى. يُسمّى بشيء من التجاوز تصنيف النص أو المستند، وإن كان هذان المصطلحان أوسع ويشملان أيضًا معالجة اللغة الطبيعية ووسم التخطيط.
ينقسم العمل إلى مهمتين، وليستا الشيء نفسه:
- الكشف — إيجاد النص. ترسم مربّعًا محكمًا حول كل منطقة نصّية ليتعلّم النموذج أين تسكن الكلمات في الصفحة. الكشف يحدّد موضع النص ويُخرِج منطقة محيطة لكل ظهور.
- التعرّف — قراءة النص. تنسخ الحروف الدقيقة داخل كل مربّع ليتعلّم النموذج ما تقوله تلك الكلمات.
الكشف يرسم المربّع. والتعرّف يقرأ ما بداخله. هكذا تُبنى المعايير المرجعية العامة بالضبط: في مهمة تحديد الموضع ضمن ICDAR للقراءة المتينة، تسِم الحقيقة الأساسية النص بمربّعات على مستوى الكلمة؛ وفي المهمة من البداية إلى النهاية تحدّد موضع كل مربّع وتعيد نسخه. النموذج المُدرَّب على الاثنين يحدّد موضع النص في صفحة جديدة ويعيد الكلمات التي تحتويها. لا تصنيف، لا نموذج يقرأ مستنداتك.
تشريح تصنيف OCR واحد
كل منطقة يعلّمها الإنسان للنموذج تحمل ثلاثة أشياء: مربّعًا، ونوعًا، والنص الدقيق.
«صافي الدخل» → ١٤٦٬٨٠٠
كلمات لك، بكسلات للآلة
انظر إلى قائمة دخل. أنت تقرأ كلمات. «قائمة الأرباح أو الخسائر الموحّدة». الإيرادات. صافي الدخل. رقمٌ في صفّ.
الآلة لا ترى شيئًا من ذلك. بالنسبة إليها، الصفحة نفسها جدارٌ من البكسلات — شبكة من نقاط الضوء والظلّ. لا كلمات. لا صفوف. لا معنى.
فيعلّمها إنسان. ترسم مربّعًا حول منطقة نصّية واحدة. تصنّف نوع النص فيها. ثم تكتب ما تقوله. ذلك الاقتران بين المربّع والنسخ هو الدرس. يخبر النموذج بشيئين في آن: هنا يسكن النص، وهذا ما يقرؤه.
هكذا فعل المجال هذا منذ سنوات. معايير المشاهد الطبيعية مثل COCO-Text تصنّف كل منطقة نصّية بمربّع محيط مع نسخ للنص المقروء، وتصنّف كل منطقة كمطبوعة آليًا أو مكتوبة باليد. (يقرأ COCO-Text النص في الصور اليومية لا في المستندات الممسوحة، لكن وصفة التصنيف — أحِط، صنّف، انسخ — هي نفسها التي يستخدمها OCR المستندات.) اكشف، ثم اقرأ.
صفحة واحدة مثالٌ واحد. وبضعة آلاف من الأمثلة مجموعة تدريب. والقاعدة لا تتزحزح أبدًا: جودة البيانات محرّك رئيسي لجودة النموذج. المربّعات المهملة تعلّم قارئًا مهملًا. والنظيفة شرطٌ لازم لنموذج يقرأ مستنداتك بنفسه.
كيف تتعلّم الآلة: الصفحات تصبح حقيقة أساسية
نموذج الـOCR لا يحفظ مستنداتك. بل يتعلّم منها. التعلّم الخاضع للإشراف يعمل من أزواج أمثلة مُصنَّفة — مُدخَل ومُخرَجه الصحيح — والهدف هو التعميم على صفحات جديدة، لا إعادة إنتاج مجموعة التدريب.
إليك الحلقة. يفتح شخصٌ صفحة. يرسم مربّعًا حول كل منطقة نصّية، ويصنّف نوعها، ويكتب ما تقوله. المربّعات تعلّم الآلة أن ترى. والنسخ يعلّمها أن تقرأ.
اجمع ما يكفي من تلك الصفحات المُصنَّفة يدويًا فتكون لديك حقيقة أساسية — أمثلة كُتبت فيها الإجابة الصحيحة سلفًا. كل خطأ في تلك الحقيقة الأساسية يعلّم النموذج شيئًا خاطئًا، لذا فالإنسان الذي ينسخها هو أهمّ شخص في خط الأنابيب.
ثم يأتي التدريب. تمرّ الصفحات عبر المعالجات الرسومية، حقبة تدريب بعد حقبة، حتى يكفّ النموذج عن مطابقة أمثلتك ويبدأ في تعلّم النمط الكامن تحتها.
الاختبار بسيط. ناوِلها صفحة لم ترها من قبل — كشف حساب بنكي جديد — وراقبها تقرأ بنفسها. المُصنِّف هو المعلّم. والنسخ هو المنهج. والنموذج لا يعرف إلا ما أراه إنسان. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
الكشف والتعرّف والاستخلاص: ثلاث طبقات، تصنيف واحد
قراءة المستند تبدو مهمة واحدة. هي ثلاث.
كشف النص يجد أين الكلمات. والتعرّف على النص يقرأ ما تقوله. واستخلاص المعلومات الرئيسية يقرّر ماذا تعني. الكشف والتعرّف هما مرحلتا الـOCR الأساسيتان؛ واستخلاص المعلومات الرئيسية (KIE) خطوة لاحقة لفهم المستند تضيف معنى دلاليًا فوق مُخرَج الـOCR.
الكشف يرسم مربّعًا حول منطقة نصّية. والتعرّف يحوّل تلك البكسلات إلى سلسلة نصّية. واستخلاص المعلومات يصنّف تلك السلسلة كشركة أو تاريخ أو إجمالي. تقسّمه المعايير القياسية بالطريقة نفسها: في مهمة ICDAR للقراءة المتينة من البداية إلى النهاية، لا تُحتسب الكلمة صحيحة إلا إذا تحدّد موضع مربّعها بدقة وطابق نسخها — فالموضع يحكم النسخ فعليًا. ومعيار الإيصالات SROIE يَسِم الكيانات كشركة وتاريخ وعنوان وإجمالي، وFUNSD يَسِم كل منطقة كترويسة أو سؤال أو إجابة أو غير ذلك.
المربّع المحيط وحده يخبر النموذج أين ينظر. والوسم التصنيفي وحده يخبره أي نوع من الأشياء وجد. ولا يخبره أيٌّ منهما بالكلمات.
تصنيف الـOCR يحمل الثلاثة معًا. ترسم المنطقة. تصنّف نوعها. تكتب النص الذي تحمله. تصنيفٌ واحد، ثلاث طبقات من الحقيقة. لهذا بنينا الـOCR كواجهة واحدة في محرك التصنيف من Annota8: اكشف وصنّف وانسخ المناطق النصّية في المرور نفسه. الإنسان يعلّم الطبقات الثلاث. والآلة تتعلّم أن تقرأ.
سبعة أنواع من الصفحات يفتحها تصنيف الـOCR
واجهة OCR واحدة، نسير بها نوع صفحة بعد آخر. إليك ما يمنحك كلٌّ منها في الواقع العملي.
- المستندات المالية. الإيصالات، والفواتير، وأوامر الشراء، والكشوف البنكية، وقوائم الدخل. يحيط إنسانٌ كل منطقة بمربّع، ويصنّفها (إجمالي، تاريخ، مبلغ)، ويكتب ما تقوله. فيقرأ نظام الحسابات الدائنة لديك الإيصال بدل انتظار موظّف يدخله يدويًا. توجد معايير مثل CORD — مجموعة بيانات عامة لتحليل الإيصالات بعد الـOCR، تقسيمتها المنشورة ٨٠٠ إيصال تدريب و١٠٠ تحقّق و١٠٠ اختبار — لأن تحليل الإيصالات مشكلة صعبة قائمة بذاتها.
- المستندات القانونية والعقود. النصوص والبنود — عنوان مادة، وبند قانون حاكم، وجدول ضمانات. ما إن يقرأ النموذج بنية العقد حتى تجد كل بند قانون حاكم عبر عشرة آلاف اتفاقية في ثوانٍ بدل أسابيع.
- الرسوم البيانية والأشكال. مخطّط أسهم: سعر OHLC، ومحور السعر، ومحور الزمن، والتسميات. أرقامٌ محبوسة في صورة تصير أرقامًا تستطيع الاستعلام عنها. ذلك هو الفرق بين التحديق في لقطة شاشة وسحبها إلى جدول بيانات.
- مستندات الهوية و«اعرف عميلك». جوازات السفر، والهويات، وإثباتات العنوان. أحِط الحقول بمربّعات، وصنّفها، وانسخها، فيكفّ تأهيل العملاء عن كونه طابور إدخال بيانات يدوي. مجموعات فهم النماذج مثل FUNSD — ١٩٩ نموذجًا حقيقيًا مُصنَّفًا وممسوحًا ضوئيًا — تُظهر لماذا تحتاج الحقول المهيكلة إلى تصنيف خاصّ بها، لا مجرّد نص خام.
- خط اليد. يفصل مخطّط الـOCR النص المطبوع عن خط اليد لسبب. الكتابة تتباين من شخص لآخر وتتّصل الحروف، ولهذا توجد مجموعات حقيقة أساسية مخصّصة مثل قاعدة بيانات IAM لخط اليد — والنموذج لا يتعلّمه إلا من صفحات نسخها إنسانٌ أولًا.
- الـOCR العربية والمتعدّدة اللغات. الحروف العربية تتّصل، وتتغيّر أشكالها بحسب الموضع، وتحمل تشكيلًا، ما يجعل تقطيع الحروف صعبًا حقًا. نحن عربيون أولًا ومبنيون لذلك. النموذج لا يقرأ العربية جيدًا إلا حين تُصنَّف الصفحات العربية جيدًا.
- المسحات التاريخية والأرشيفية. حبرٌ باهت، وتخطيطات غريبة، وخطوط قديمة. أحِط المناطق النصّية بمربّعات، وانسخها، فيتحوّل قرنٌ من الورق إلى نصّ قابل للبحث.
خيطٌ واحد يجري في السبعة جميعًا: أي صفحة تصير بيانات تدريب لحظة يقرؤها إنسانٌ أولًا. ارسم المربّع، وصنّف المنطقة، واكتب النص، فتكفّ الصفحة عن كونها جدارًا من البكسلات وتبدأ في تعليم الآلة أن تقرأ.
كيف يقوم محرك التصنيف من Annota8 بالـOCR
بنينا الـOCR كواجهة واحدة داخل محرك التصنيف من Annota8. العمل يبقى بسيطًا: اكشف وصنّف وانسخ المناطق النصّية.
افتح صفحة. كشف حساب بنكي، أو إيصال، أو قائمة دخل، أو مخطّط أسهم. ثم يعمل عليها شخصٌ سطرًا بسطر:
- ارسم مربّعًا. مستطيلًا، أو مضلّعًا حين ينحني النص أو يميل بزاوية.
- صنّف نوعه. اختر نوع المنطقة. نص مطبوع. خط يد. إجمالي/مبلغ. تاريخ. أنت تضبط المخطّط.
- انسخه. اكتب ما تقوله المنطقة في حقلها الخاصّ، مربّعًا واحدًا في كل مرة.
نمط المربّع والوسم والنص ذاك واجهة واحدة قابلة للضبط ضمن مكتبة من ١٨٠ واجهة تصنيف عبر ٧ وسائط. المحرك نفسه الذي يقرأ المستندات يتعامل أيضًا مع الصورة والنص والفيديو والصوت والإشارات وHTML — وهو مباشر اليوم.
وإليك الجزء الصادق. يستطيع النموذج أن يقترح مربّعات ونصًّا ليؤكّدها إنسانٌ أو يصحّحها — نمط «الإنسان في الحلقة» القياسي الذي يسرّع الوسم. لكن الإنسان يبقى في القيادة. النموذج يقترح. والإنسان يؤكّد ويصحّح ويقرّر ما هي الحقيقة الأساسية. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه. وتستطيع حتى أن تسأل بيانات تصنيفك بلغة واضحة لتتبّع الجودة والتقدّم.
واجهة OCR واحدة، يُعاد توجيهها لأي مستند
إليك الجزء الذي يغفله معظم الفرق. أنت لا تبني واجهة جديدة لكل مستند — بل تعيد توجيه الواجهة نفسها.
واجهة الـOCR خلف قائمة دخلنا ضبطٌ واحد. أعِد تسمية وسوم أنواع المناطق — استبدل «إجمالي/مبلغ» بـ«عنوان مادة» فتقرأ نصًّا قانونيًا بدل ميزانية. أضِف حقلًا، فيحمل كل مربّع الآن تاريخًا أو عملةً بجانب نصّه. بدّل اللغة إلى العربية، فتقرأ اللوحة نفسها من اليمين إلى اليسار.
اختر شكلك بحسب المهمة. أسطر مطبوعة مستقيمة على إيصال؟ المربّع محكمٌ بما يكفي. نصٌّ منحنٍ أو مائل على مخطّط أو نموذج مختوم؟ ارسم مضلّعًا ليلتصق بالنص بدل أن يبتلع خلفيةً تفسد جودة الحقيقة الأساسية — وهذا بالضبط سبب استخدام معايير النص المنحني وسوم المضلّعات.
المحرك نفسه. إيصال، وعقد، ومخطّط أسهم، وكشف حساب بنكي — واجهة واحدة، يُعاد توجيهها.
لا تصنيف، لا نموذج، لا ذكاء اصطناعي يقرأ مستنداتك
جرّد الأمر فالقاعدة بسيطة. لا تصنيف، لا نموذج، ولا ذكاء اصطناعي يقرأ مستنداتك. كل نموذج يقرأ تعلّم من إنسانٍ أحاط كل منطقة نصّية بمربّع ونسخها أولًا. عربيون أولًا بالتصميم — واجهة الـOCR نفسها تقرأ الصفحات الإنجليزية والمالية والقانونية والمكتوبة باليد بالكفاءة ذاتها. معيار ICDAR 2019 SROIE، على سبيل المثال، يصنّف كل صورة بمربّعات نصّية محيطة ونسخ كل مربّع — تلك هي الحقيقة الأساسية التي يتعلّم منها النموذج.
تلك هي الحلقة كاملةً. يرسم إنسانٌ المربّع، ويسمّي المنطقة، ويكتب ما تقوله. وتشاهد الآلة ما يكفي من الأمثلة لتقرأ صفحة لم ترها من قبل.
بنينا محرك التصنيف لهذا العمل بالذات، كي يبقى من يعلّمون في القيادة. علّمها أن ترى. علّمها أن تسمع. علّمها أن تقرأ. احجز عرضًا على annota8.ai.
لا تصنيف، لا نموذج — ولا ذكاء اصطناعي يقرأ مستنداتك.البشر يعلّمون الآلة
أسئلة شائعة
تصنيف الـOCR هو عمل تعليم الآلة أن تقرأ. يرسم شخصٌ مربّعًا حول كل منطقة نصّية في صورة، ويصنّف نوع النص فيها، ثم يكتب بالضبط ما تقوله. تصبح تلك الأمثلة المُصنَّفة بيانات التدريب التي يتعلّم منها نموذج التعرّف الضوئي على الحروف. بالنسبة إلى الآلة، يبدأ المستند جدارًا من البكسلات؛ والتصنيف هو كيف يتحوّل إلى كلمات.
تعمل منطقةً تلو الأخرى على صفحة ممسوحة ضوئيًا أو صورة. ارسم مربّعًا (أو مضلّعًا) حول كتلة نصّية، وأسنِد إليها وسمًا مثل «نص مطبوع» أو «خط يد» أو «تاريخ» أو «إجمالي»، ثم انسخ الحروف التي بداخلها. كرّر ذلك حتى تُحاط كل منطقة نصّية بمربّع وتُصنَّف وتُنسَخ. اكشف وصنّف وانسخ: تلك هي الحلقة كاملةً، وهي الحلقة التي بنينا لها واجهة واحدة في محرك التصنيف من Annota8.
يُستخدَم أينما احتاجت جهة إلى آلة تقرأ المستندات على نطاق واسع: قوائم الدخل، وكشوف الحسابات البنكية، والإيصالات، وأوامر الشراء، والفواتير، والنصوص القانونية، وحتى النص داخل الرسوم البيانية. بنكٌ يؤتمت معالجة الكشوف، أو شركة تقنية مالية تقرأ الإيصالات، أو فريق قانوني يستخرج البنود — كلهم يحتاجون إلى نموذج OCR أولًا، وكل نموذج منها يحتاج إلى صفحات مُصنَّفة يدويًا قبل أن يقرأ مستندًا جديدًا واحدًا.
الـOCR هو النموذج الذي يقرأ. وتصنيف الـOCR هو العمل البشري الذي يعلّمه كيف يقرأ. لبناء نموذج لمستنداتك أو ضبطه، يأتي التصنيف أولًا: تصنّف صفحات الحقيقة الأساسية يدويًا، ويتدرّب النموذج عليها، وعندها فقط يقرأ صفحة لم يرها من قبل. الـOCR الجاهز يقرأ صفحات كثيرة لأن شخصًا صنّف من قبل. لا تصنيف، لا نموذج يقرأ مستنداتك.
الكشف يجد أين يقع النص؛ والتعرّف يقرأ ما يقوله النص. الكشف يرسم المربّع حول منطقة نصّية؛ والتعرّف ينسخ الحروف داخل ذلك المربّع. كثير من خطوط أنابيب الـOCR تشغّلهما مرحلتين، ولهذا تلتقط مهمة تصنيف OCR جيدة الاثنين معًا: هندسة المنطقة والنسخ. تفصل المعايير المرجعية العامة مثل مسابقات ICDAR للقراءة المتينة بين الكشف والتعرّف بوصفهما مهمتين منفصلتين، للسبب نفسه تمامًا.
مربّعات محكمة، ووسوم متّسقة، ونسخ دقيق. ينبغي أن يلتصق المربّع بالنص دون خلفية زائدة ودون قطع للحروف، وأن يتّبع نوع المنطقة مخطّطًا واحدًا متّفقًا عليه بين كل المُصنِّفين، وأن يطابق النسخُ الصفحةَ حرفًا بحرف، بما في ذلك الترقيم وحالة الأحرف. جودة البيانات محرّك رئيسي لجودة النموذج: النموذج المُدرَّب على مربّعات مهملة ونسخ مليء بالأخطاء يتعلّم أن يقرأ بإهمال. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
نعم، تقرأ نماذج الـOCR معظم النص المطبوع النظيف بنفسها، ويمكنك ملء التصنيفات مسبقًا بأحدها لتسريع الوسم. لكنها لا تزال تخطئ في المسحات الباهتة، والخطوط غير المألوفة، وخط اليد، والجداول، والصور منخفضة الدقة، وحرفٌ خاطئ في إجمالٍ أو رقم حساب مكلف. تُظهر معايير ICDAR انخفاض دقة التعرّف على النص المتدهور والمكتوب باليد، لذا يتحقّق إنسانٌ من مُخرَج الآلة ويصحّحه. النمط هو القيادة البشرية: النموذج يقترح، والإنسان يؤكّد الحقيقة الأساسية.
استخدم مستطيلًا للأسطر النصّية المستقيمة المعتدلة؛ فهو أسرع ويناسب معظم المستندات المطبوعة. واستخدم المضلّع حين يكون النص منحنيًا أو مائلًا أو مُدارًا أو ملتفًّا حول شكل، حيث يبتلع المستطيل خلفيةً أو يقطع حروفًا. توجد معايير ICDAR للنص المنحني لأن المستطيلات تفشل مع هذا النوع من النص. في واجهة الـOCR من Annota8 تستطيع رسم أيٍّ منهما على لوحة الصورة نفسها وتبديلهما لكل منطقة.
خط اليد والعربية كلاهما أصعب على الآلة، لذا يجب أن يكون التصنيف أكثر عناية. خط اليد يتباين من شخص لآخر وتتّصل حروفه، ولهذا توجد مجموعات حقيقة أساسية مخصّصة مثل قاعدة بيانات IAM لخط اليد. وتضيف العربية التدفق من اليمين إلى اليسار، والوصل المتّصل، وأشكال حروف تتغيّر بحسب موضعها، مع مدوّنات بحثية مثل قاعدة بيانات KHATT المبنية لخط اليد العربي. نحن عربيون أولًا بالتصميم، ويعامل مخطّط الـOCR النص العربي والمكتوب باليد كأنواع مناطق قائمة بذاتها.
ابدأ بالمستندات التي تريد قراءتها فعلًا: اجمع مجموعة تمثيلية من الصفحات، واتفِق على مخطّط لأنواع المناطق، وصنّفها بالكشف مع النسخ حتى تجمع ما يكفي من الحقيقة الأساسية للتدريب. تمنحك واجهة الـOCR من Annota8 مربّعات ومضلّعات ووسوم مناطق وحقل نسخ فوق صور مستنداتك، فيستطيع فريقك أن يكشف ويصنّف وينسخ في مكان واحد. احجز عرضًا على annota8.ai لتراها على مستنداتك.
المصادر ومزيد من القراءة
- AWS — ما هو الـOCR؟
- Rosetta: كشف النص والتعرّف عليه على نطاق واسع (arXiv 1910.05085)
- docTR (mindee) — معمارية الكشف + التعرّف
- التعلّم العميق للـOCR (Nanonets)
- مسابقة ICDAR للقراءة المتينة — مهام النص المركّز في المشاهد
- COCO-Text: مجموعة بيانات ومعيار لكشف النص والتعرّف عليه (arXiv 1601.07140)
- Adobe — ما هو البكسل
- Grant Thornton — مثال قوائم مالية موحّدة وفق IFRS (قائمة الأرباح أو الخسائر)
- دورة Google لتعلّم الآلة — التعلّم الخاضع للإشراف
- دورة Google لتعلّم الآلة — التعميم
- مسرد Google لتعلّم الآلة — الحقبة (Epoch)
- ICDAR2019 SROIE: التعرّف الضوئي على الإيصالات الممسوحة واستخلاص المعلومات (arXiv 2103.10213)
- FUNSD: مجموعة بيانات لفهم النماذج في المستندات الممسوحة المشوّشة (arXiv 1905.13538)
- CORD: مجموعة إيصالات موحّدة لتحليل ما بعد الـOCR (clovaai، GitHub — تقسيمة ٨٠٠/١٠٠/١٠٠)
- Investopedia — مخطّط OHLC (افتتاح-أعلى-أدنى-إغلاق)
- قاعدة بيانات IAM لخط اليد (FKI، HEIA-FR)
- KHATT: قاعدة بيانات عربية مفتوحة لخط اليد دون اتصال (ScienceDirect)
- تطوّرات وتحدّيات في الـOCR العربية: مسحٌ شامل (arXiv 2312.11812)
- Total-Text: معيار النص المنحني بوسوم المضلّعات (arXiv 1710.10400)
- Appen — نهج «الإنسان في الحلقة» لجودة بيانات الذكاء الاصطناعي
- «إن أدخلت نفاية أخرجت نفاية» مُراجَعةً — Quantitative Science Studies (MIT Press)
لنُعلّمها.
أن ترى. أن تسمع. أن تفهم.
ضع مستنداتك أمام محرك التصنيف من Annota8 وشاهد نموذجًا يتعلّم أن يقرأها — البشر في القيادة، في كل خطوة.
احجز عرضًا ←