ما هو تصنيف النقاط المفصلية؟
بدقّة إذن: تصنيف النقاط المفصلية يضع نقاط (س، ص) على المعالم المهمة لجسمٍ ما — المفاصل، وملامح الوجه، وأجزاء الأداة — كي يتعلّم النموذج بنيته ووضعيته، لا مجرد موضعه. ١
تصنيف النقطة المفصلية ثلاثة أشياء: النقطة (إحداثي س، ص على معلم)، والهيكل (الحوافّ التي تربط النقاط في وضعية يمكنك قراءتها)، وعلم رؤية (مرئية أو محجوبة أو غائبة — كي يعرف النموذج أن المفصل المختفي موجود لا أنه زال). ٣
تستخدم المهام المختلفة مجموعات نقاط مختلفة — تعرّف COCO ١٧ نقطة جسمية؛ وتتتبّع MediaPipe ٣٣ للجسم، و٢١ لكل يد، و٤٦٨ للوجه. والنقاط المفصلية تجيب عن سؤال غير الذي تجيب عنه التصنيفات الأخرى: المربّع يقول أين الجسم، والتقطيع يقول شكله، والنقاط المفصلية تقول كيف بُني واتّخذ وضعيته. لهذا تغطّي أداة واحدة عدّاءً وسمكة سلمون — مجموعة النقاط تتغيّر، والمهمة لا. احتفظ بهذه الفكرة؛ فهي جوهر الدليل كلّه.
النقاط المفصلية مقابل المربّع المحيط مقابل المضلّع مقابل التقطيع
أربع طرق لتصنيف جسم. تجيب عن أربعة أسئلة مختلفة. اختر ما يطابق ما يحتاج النموذج إلى تعلّمه.
| نوع التصنيف | ما يلتقطه | شكل المُخرَج | استخدمه حين يحتاج النموذج أن يعرف… |
|---|---|---|---|
| المربّع المحيط | الموقع | مستطيل x, y, w, h | أين الجسم — الكشف والعدّ والتتبّع |
| المضلّع | الشكل التقريبي | رؤوس مرتّبة تحدّ الجسم | حدًّا أضيق من المربّع، دون كلفة كل بكسل |
| التقطيع | الشكل الدقيق | قناع لكل بكسل | الظلّ الدقيق — أين ينتهي الجسم، بكسلًا بعد بكسل |
| النقطة المفصلية | البنية والوضعية | نقاط (x, y, v) + حوافّ هيكل | كيف بُني الجسم واتّخذ وضعيته — المفاصل والمعالم والحركة |
المربّع يخبر النموذج أن العدّاء هنا. والقناع يخبره بالبكسلات التي يشغلها العدّاء بالضبط. والنقاط المفصلية تخبره أن الركبة منثنية، والذراع تندفع للخلف، والجذع يميل. ٩٣٩
ذلك هو التمييز الذي يحسم ميزانية تصنيفك. إن كنت تحتاج فقط إلى إيجاد الأجسام وعدّها، فالمربّعات أرخص. وإن كنت تحتاج إلى قراءة الوضعية أو الحركة أو التعبير — خطوة، أو قرصة، أو ابتسامة — فالنقاط المفصلية هي النوع الوحيد الذي يحمل ذلك.
هذا أنظف خطّ في تصنيف الرؤية الحاسوبية: الموقع مقابل الشكل مقابل البنية.
لماذا يهمّ تصنيف النقاط المفصلية: النقاط هي الدرس
عدّاء بأقصى سرعته، بالنسبة إلى الآلة، شبكة بكسلات. لا أكثر. ضع نقطة على الكتف والمرفق والمعصم والركبة، واربطها — الآن صار لديها وضعية. «٤١٢، ٢٨٧» ليست كتفًا حتى يقرّر شخصٌ أنها كذلك. ذلك القرار، مكرّرًا عبر كل إطار، هو الدرس.
فبيانات التدريب ليست مكوّنًا جانبيًا؛ إنها الدرس. النموذج لا يفوق جودة تلك الكومة من الأمثلة الموضوعة باليد: نقطة على بُعد بضع بكسلات من المفصل فيُكرّر الخطأ على نطاق واسع. (وجد مدقّقون أخطاء تصنيف تبلغ ٣٫٣٪ فأكثر عبر عشر مقايسات تعلّم آلي كبرى. ١٨) تستطيع التصنيف المسبق بنموذج، لكن التخمين ليس حقيقة أساسية — شخصٌ يصحّحه حتى دقة مركز المفصل ويعتمده.
البشر يعلّمون الآلة. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
البشر يعلّمون الآلة.ذكاؤك الاصطناعي ليس أفضل ممّن علّموه
كيف يعمل تصنيف النقاط المفصلية فعليًا
يجري بالخطوات الست نفسها في كل مرة — وحدها النقاط تتغيّر: (١) عرّف المخطط — أي المعالم موجودة وكيف يربطها الهيكل؛ (٢) ضع كل نقطة بدقة مركز المفصل؛ (٣) صنّف ما لا تراه (مرئي / محجوب / غائب)؛ (٤) أبقِ تعريفًا واحدًا لكل معلم عبر المصنّفين؛ (٥) اضبط الجودة باتفاق المصنّفين ومراجعٍ يضع الإجابة الذهبية؛ (٦) صدّر إلى JSON بنمط COCO يدخل التدريب مباشرة. ٢٠
محرك التصنيف من Annota8 يفعل هذا بالضبط: أداة نقاط مفصلية مرمّزة بالألوان، ومعيار ذهبي مكتوب بشريًا، وتصنيف مسبق اختياري بالتعلّم الآلي (الآلة تقترح، والإنسان يقرّر)، وتصدير قياسي — واحدة من ١٨٠ واجهة عبر ٧ وسائط، كلّها مباشرة. احجز عرضًا على [email protected].
صيغة COCO للنقاط المفصلية، مُبيَّنةً (لا مجرد موصوفة)
تخبرك معظم الأدلّة أن COCO تخزّن النقاط المفصلية كـ«مصفوفة ٣×١٧ من س، ص، v». وقليل منها يُريك القطعة الفعلية. ها هي — الـJSON بالضبط الذي يستطيع المطوّر نسخه.
{
"categories": [
{
"id": 1,
"name": "person",
"keypoints": [
"nose", "left_eye", "right_eye", "left_ear", "right_ear",
"left_shoulder", "right_shoulder", "left_elbow", "right_elbow",
"left_wrist", "right_wrist", "left_hip", "right_hip",
"left_knee", "right_knee", "left_ankle", "right_ankle"
],
"skeleton": [
[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],
[6,7],[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],
[2,4],[3,5],[4,6],[5,7]
]
}
],
"annotations": [
{
"id": 1001,
"image_id": 42,
"category_id": 1,
"bbox": [212, 88, 130, 410],
"num_keypoints": 15,
"keypoints": [
267,120,2, 280,110,2, 255,110,2, 300,118,1, 240,118,1,
330,200,2, 210,205,2, 360,290,2, 185,295,2, 375,370,2,
170,378,2, 315,330,2, 235,332,2, 320,440,2, 232,442,2,
0,0,0, 0,0,0
]
}
]
}ثلاثة أشياء تقرأها من هذا:
مصفوفة keypoints مسطّحة. إنها قائمة بطول 3k — لنقاط الشخص الـ١٧ ذلك ٥١ رقمًا: x1,y1,v1, x2,y2,v2, …. ويُثبّت ترتيبَها قائمةُ الأسماء في categories[].keypoints أعلاها. ٣٧
علم الرؤية هو الرقم الثالث في كل ثلاثية. v=2 مرئية، v=1 مصنَّفة لكن محجوبة، v=0 غير مصنَّفة (وحينها x=y=0). في المثال، كلا الكاحلين 0,0,0 — خارج الإطار، فيكون num_keypoints ١٥، لا ١٧. ٢٢٣٧
الـskeleton قائمة حوافّ. كل زوج نقطتان مفصليّتان مُفهرستان بدءًا من ١ ليُربطا — [16,14] يصل left_ankle بـleft_knee. الهيكل للبنية والتصوير؛ لا يضيف بيانات، بل يربطها. ٣٧
ذلك هو المخطط كلّه. نقاط، ورؤية، وحوافّ. أدخله في أي خط إنتاج متوافق مع COCO فيتدرّب.
ثنائي وثلاثي الأبعاد وكامل الجسم: أي مجموعة نقاط مفصلية تستخدم
«تصنيف النقاط المفصلية» ليس مهمة واحدة. فالأبعاد وعدد النقاط يتغيّران بحسب السؤال الذي تجيب عنه. ثلاثة أنماط، بوضوح:
نقاط ثنائية الأبعاد — (س، ص). نقطة على مستوى الصورة. هذا الافتراضي ويغطّي معظم المجال: وضعية الرياضة، والإيماءة، ومعالم الوجه، وتتبّع الحيوانات. مجموعة COCO ذات الـ١٧ نقطة للشخص ثنائية. استخدمها حين يحمل المنظر المسطّح للكاميرا الإشارة التي تحتاجها. ٣
نقاط ثلاثية الأبعاد — (س، ص، ع). تضيف العمق، فتُعاد بناء الوضعية في الفضاء، لا على الصورة وحدها. تستنتج MediaPipe Pose وMediaPipe Hands كلتاهما معالم ثلاثية الأبعاد؛ والـع عمق نسبي، لا مسافة مترية حقيقية. استخدمها حين تهمّ الزاوية خارج المستوى — يدٌ تمتدّ نحو متحكّم واقع افتراضي، أو جسدٌ يلتفّ مبتعدًا عن الكاميرا. ٦٧
كامل الجسم — COCO-WholeBody، ١٣٣ نقطة مفصلية. الجسم + الوجه + اليدان + القدمان في تصنيف واحد: ١٧ للجسم، و٦٨ للوجه، و٤٢ لليدين (٢١ لكل يد)، و٦ للقدمين. استخدمها حين يتعيّن على نموذج واحد أن يقرأ الوضعية والتعبير وتفاصيل الأصابع دفعةً واحدة — لغة الإشارة، والتفاعل الدقيق، والتقاط الأفاتار. وهو الأغلى تصنيفًا، فلا تلجأ إليه إلا حين تحتاج فعلًا إلى المناطق الأربع. ١٢
القاعدة العملية: ابدأ بثنائي الأبعاد. أضف الـع حين يغيّر العمق الإجابة. واذهب إلى كامل الجسم حين يحمل الجسم والوجه واليدان الدرس جميعًا.
المزيد من النقاط والأبعاد يعني مزيدًا من الكلفة ومزيدًا من مواضع عدم الاتّساق. كل معلم إضافي شيء آخر على إنسان أن يضعه بالطريقة نفسها، في كل مرة. والمخطط الذي تختاره قرار ميزانية بقدر ما هو قرار تقني.
حالة استخدام — الرياضة واللياقة والأداء: كل خطوة مجموعة نقاط

راقب عدّاءً بأقصى سرعته. ترى العين بقعةً ضبابية؛ ويرى نموذج النقاط المفصلية بنية — نقطة على كل مفصل، مربوطةً في هيكل، فصار للحركة الآن رياضياتها: زوايا المفاصل، وطول الخطوة، والإيقاع، وتماثل اليمين واليسار، وأين تنهار الوضعية مع حلول التعب.
كان هذا يستلزم مختبرًا مليئًا بالعلامات العاكسة. أما الآن فيضع النموذج النقاط من الفيديو مباشرة — وتُبلّغ متتبّعات العَدْو بلا علامات عن أخطاء زاوية مفصلية تبلغ ٣٫٢–٥٫٥ درجة فقط مقابل المرجع القائم على العلامات. ٢٨ وقد دخلت دائرة الأضواء أيضًا: يتتبّع Hawk-Eye ٢٩ نقطة هيكلية لكل لاعب ويحتسب التسلل شبه الآلي منذ ٢٠٢٢. ٣٠
لكن لا شيء من ذلك يعمل دون إنسان أولًا. لا يعرف النموذج «ركبة» إلا لأن المصنّفين وضعوا آلاف الركب، بدقة، في مركز المفصل — الحقيقة الأساسية التي يتعلّم منها الخطوة. البشر يعلّمون الآلة. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
حالة استخدام — السيارات والواقع الممتد: داخل المقصورة، وعند أطراف أصابعك
حالتا استخدام. والبداية نفسها: ضع نقطة.
مراقبة السائق: السيارة تتعلّم أن تراقب السائق
يراقب نظام مراقبة السائق (DMS) شيئًا واحدًا. الشخص خلف المقود.
يتتبّع الرأس. والعينين. ونقاطًا مفصلية على الوجه تقول إلى أين تنظر ومدى يقظتك.
ناعس؟ تنغلق الجفون أطول. وتنخفض نسبة عرض العين. مشتّت؟ يلتفت الرأس عن الطريق. يبني الباحثون هذه الأنظمة على نقاط معالم الوجه ووضعية الرأس، حاسبين مقاييس انغلاق العين والتثاؤب إطارًا بإطار. ٣٢٣٣
لا شيء من ذلك يعمل دون حقيقة أساسية.
على شخصٍ أن يصنّف زوايا العين. والأنف. وزاوية الرأس. إطارًا بعد إطار، عبر السائقين، والإضاءة، والنظارات، والليل. لا يرى النموذج إلا ما علّمه إنسانٌ أن يراه.
لم يعد هذا رفاهيةً. فـEuro NCAP يضع مراقبة السائق المباشرة جزءًا من تقييم السلامة. ويُتوقَّع من السيارات تتبّع اتجاه النظر ووضعية الرأس في الزمن الحقيقي، والتنبيه إلى النعاس عند سرعات الطرق السريعة. لم يعد استنتاج الانتباه من إدخال المقود وحده كافيًا. ٣٤٣٥٣٦
وذلك الضغط حاضر حيثما تتّجه مراقبة السائق — ويقع أثقل ما يقع حيث الطرق أشدّ فتكًا. حوادث الطرق هي السبب الأول للوفاة في السعودية، حيث تستهدف رؤية ٢٠٣٠ أقل من ١٠ وفيات طرق لكل ١٠٠٬٠٠٠ نسمة بحلول ٢٠٣٠. سيارة تستطيع أن تدرك متى يغفو سائقها ليست ميزة هناك — إنها حياة تُنقَذ. ٤٠٤١
وكل واحدة من تلك السيارات تأتي مزوّدةً بنموذج مدرَّب على نقاط مفصلية مصنَّفة.
الأيدي: الواجهة بلا أزرار
انتقل الآن إلى الأيدي.
لليد ٢١ نقطة مفصلية. المعصم، والمفاصل، ومفاصل الأصابع، وأطراف الأصابع. تستنتج MediaPipe Hands الـ٢١ جميعًا كمعالم ثلاثية الأبعاد من إطار كاميرا واحد. تلك خريطة يد. ٧
بتلك الخريطة، تقرأ الآلة ما تفعله يداك:
- إدخال الواقع المعزّز والافتراضي. تصير القرصة نقرة. والقبضة إمساكًا. بلا متحكّم. ٣٨
- الواجهات بلا لمس. لوّح، ومرّر، وأشر. تحكّم في شاشة دون لمسها. ٤٢
- التعرّف على لغة الإشارة. تتبّع اليدين، واقرأ الإشارة، وحوّلها نصًّا. تتبّع النقاط المفصلية في صميم هذه الأنظمة. ٣٧
لكن النموذج الذي وجد تلك النقاط الـ٢١؟ دُرِّب على أيدٍ صنّفها إنسان أولًا. وبحسب رواية Google نفسها، بُني نموذج معالم اليد في MediaPipe على نحو ٣٠٬٠٠٠ صورة واقعية، كلٌّ مصنَّفة يدويًا بـ٢١ إحداثيًا ثلاثي الأبعاد. ٧
وذلك هو المغزى كلّه. تقرأ الآلة اليد لأن شخصًا علّمها أين مفاصل اليد.
نبني مجموعات بيانات النقاط المفصلية نفسها بالضبط في محرك التصنيف من Annota8. نقاط ملوّنة على وجه. مفاصل على يد. معيار ذهبي مكتوب باليد كالإجابة الصحيحة. تصدير كـJSON قياسي. واحدة من ١٨٠ واجهة تصنيف عبر ٧ وسائط، كلّها مباشرة.
من سائق ناعس إلى إصبع تقرص، يبدأ الأمر بنقطة. وبإنسان وضعها.
حالة استخدام — الوجوه والأجساد: من مرشّحات الواقع المعزّز إلى غرفة العمليات
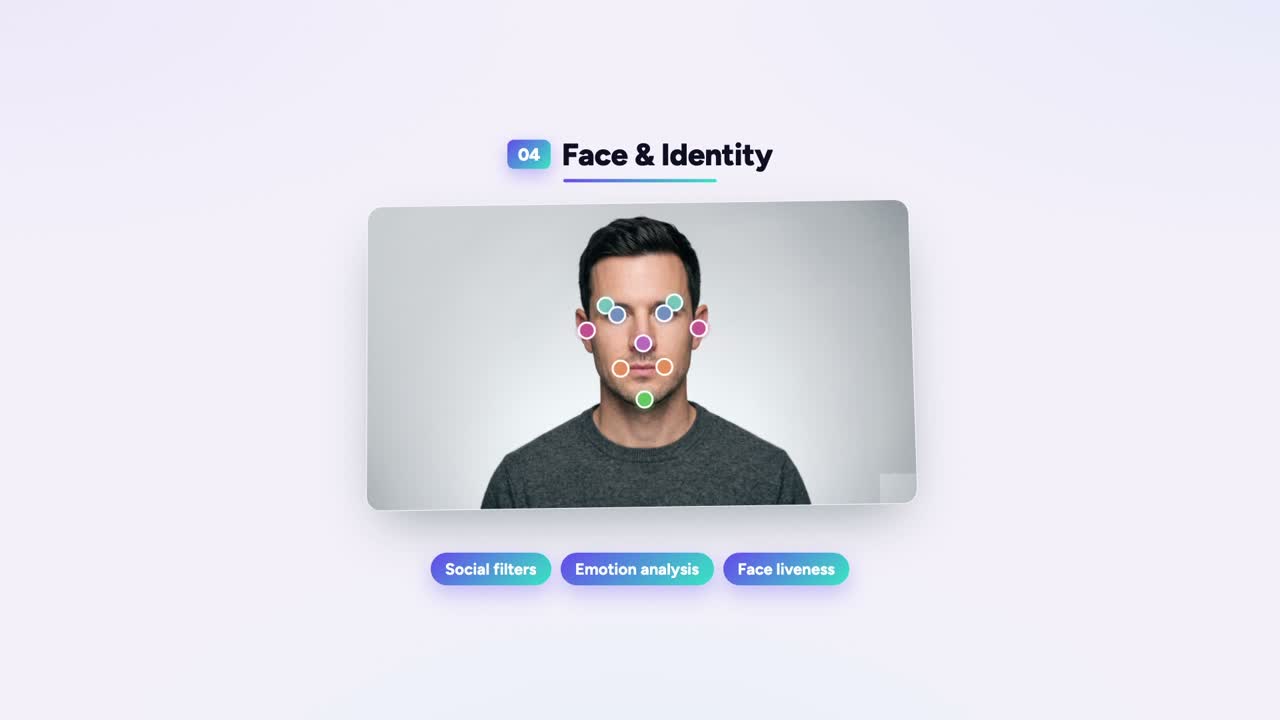
ضع نقاطًا كافية على وجه، فتتوقّف الآلة عن رؤية البكسلات. وتبدأ برؤية وجه.
تلك هي اللعبة كلّها. أداة النقاط المفصلية نفسها التي تُلصِق هيكلًا على عدّاء تُلصِق شبكةً على وجه إنسان. الفكرة نفسها. معالم مختلفة.
الوجوه: المرشّحات والتعبيرات وإثبات أنك حقيقي
على مرشّح الوجه أن يعرف أين وجهك قبل أن يضع عليه نظارة شمسية. فتصنّف المعالم: زوايا العين، طرف الأنف، حوافّ الشفة، خطّ الفك. يستخدم نموذج dlib الكلاسيكي ٦٨ منها، مدرَّبًا على وجوه مصنَّفة يدويًا. ويقدّر MediaPipe Face Mesh من Google ٤٦٨ نقطة ثلاثية الأبعاد على وجه واحد من كاميرا عادية — بلا مستشعر عمق. ٤٣٤٤٤٥
بتلك النقاط يتتبّع المرشّح أنفك حين تدير رأسك.
ادفع أبعد فتصل إلى تحليل التعبير. يرمّز الباحثون الوجوه بنظام ترميز حركات الوجه (FACS) — الذي طوّره بول إكمان ووالاس فريزن ونُشِر عام ١٩٧٨ — الذي يفكّك التعبيرات إلى «وحدات حركة»، الحركات الصغيرة لعضلات الوجه التي تصنع ابتسامة أو عبوسًا. صنّف المعالم، وتتبّع كيف تتحرّك، فيقرأ النموذج وحدات الحركة تحتها. ٤٦٤٧
ثم هناك الحيوية. أهذا وجه حقيقي، أم صورة رُفِعت أمام الكاميرا؟ ذلك كشف هجمات العرض، وله معيار: ISO/IEC 30107-3، الذي يحدّد كيف تختبر المختبرات قدرة النظام على تمييز شخص حيّ من انتحال. وبيانات التدريب خلفه وجوه مصنَّفة — حقيقية ومزيّفة — مصنَّفة كي تتعلّم الآلة الفرق. ٤٨٤٩
بنى مؤسّسانا هذا النوع من الإدراك في Affectiva وSmart Eye. وكان العمل يعود دائمًا إلى الشيء نفسه: لا يقرأ النموذج الوجوه إلا بقدر جودة من صنّفوا الوجوه التي تعلّم منها.
الرعاية الصحية: الدقّة حيث تهمّ
الطبّ حيث تصير النقاط المفصلية جادّة.
في الجراحة، يتتبّع الباحثون نقاطًا على الأدوات — طرف الأداة، وقاعدتها — كي يعرف النظام أين الأداة في الإطار. وهو صعب. فالأطراف صغيرة، والأدوات مفصلية، وتُحجَب، وتتغيّر الإضاءة، ويضبب الفيديو. كل واحدة من تلك النقاط تبدأ تصنيفًا بشريًا على إطار من فيديو جراحي. ٥٠٥١
في طبّ الأسنان والتقويم، عماد العمل التحليل القياسي للجمجمة: تصنيف معالم على أشعّة جانبية للجمجمة لتخطيط العلاج. وفعله باليد بطيء وغير متّسق. وتضع نماذج التعلّم العميق تلك المعالم آليًا الآن — لكنها دُرِّبت على صور أشعّة صنّفها طبيبٌ أولًا. ٥٢٥٣
في التأهيل، هناك تحليل المشية. يتتبّع تقدير الوضعية بلا علامات نقاطًا مفصلية للجسم من فيديو عادي لقياس كيف يمشي المرء — مُتحقَّقًا منه لدى مرضى ما بعد السكتة والشلل الرعّاش مقابل أنظمة التقاط حركة مرجعية. ٥٤٥٥٥٦
تحذير نلتزم به: هذه أدوات بحث ومساعدة، لا تشخيصات. النموذج يقترح. والطبيب يقرّر. نبني التصنيف؛ ولا نقدّم ادّعاءات سريرية.
أداة واحدة، عالمان
شبكة وجه وأشعّة جراحية لا يتشابهان البتّة. أما لأداة النقاط المفصلية فهما المهمة نفسها: ضع نقطة مصنَّفة في موضعها تمامًا.
ذلك ما تفعله أداة النقاط المفصلية في محرك التصنيف لدينا — نقاط ملوّنة مصنَّفة موضوعة بدقة المعلم مقابل معيار ذهبي مكتوب باليد، مُصدَّرة كـJSON متوافق مع COCO. واحدة من ١٨٠ واجهة عبر ٧ وسائط، كلّها مباشرة.
من مرشّح سيلفي إلى علاج جذر سنّ، يبدأ الأمر بنقطة. وإنسانٌ يضعها هناك.
حالة استخدام — الزراعة والماشية والاستزراع المائي: من عدّاء إلى سمكة سلمون
نقطة على ركبة عدّاء ونقطة على ذيل سمكة سلمون هما الفكرة نفسها. صنّف المعلم. واربط البنية. وعلّم الآلة ما يهمّ.
غادر تصنيف الوضعية الصالة الرياضية منذ زمن بعيد. فهو يجري الآن في الحقول، وفي الحظائر، وفي الأقفاص البحرية.
إليك كيف يبدو ذلك في العالم الحقيقي.
المحاصيل: أين تقطع، ومتى تقطف.
الفراولة ليست مجرد «ناضجة أو لا». يحتاج روبوت الحصاد أن يعرف الموضع الدقيق للإمساك والموضع الدقيق للقطع.
فيصنّف الباحثون نقاطًا مفصلية على الثمرة نفسها. تصنّف مجموعة بيانات عامة واحدة خمس نقاط لكل فراولة: نقطة القطف، وأعلى الثمرة وأسفلها، ونقطتا الإمساك اليسرى واليمنى للقابض. وتُصنَّف درجة النضج أيضًا — باللون، من غير الناضجة (أخضر/أبيض) إلى نصف الناضجة إلى تامّة النضج (أحمر). ٥٧٥٨٥٩
تلك التصنيفات هي الحقيقة الأساسية. ويتعلّم الروبوت أين يمدّ يده بنسخ آلاف النقاط الموضوعة بشريًا.
الماشية: العَرَج الذي لا تراه العين.
البقرة العرجاء تكلّف مالًا وتشير إلى ألم. وأبكر علامة تغيّر في المشية — خفيّ، يسهل تفويته في مزرعة مزدحمة.
النقاط المفصلية تلتقطه. يصنّف المصنّفون نقاطًا تشريحية على البقرة عبر إطارات الفيديو. استخدمت دراسة واحدة خمس نقاط مفصلية على طول الظهر لقياس التقوّس، إضافةً إلى نقطتي رأس لرصد وضعية الرأس. ومن تلك النقاط المتتبَّعة يقرأ النموذج الوضعية والمشية، ثم يرصد العَرَج. ٦٠
تُبلّغ الأنظمة المنشورة عن دقّة عَرَج في أواخر الثمانينيات إلى أواخر التسعينيات بالمئة — متتبّعٌ قائم على DeepLabCut نحو ٨٧–٩٠٪، ونظام وضعية آخر ٩٤–١٠٠٪ — كلّها مبنية على وضعية حيوانية مصنَّفة بشريًا. ٦٠٦١
الاستزراع المائي: عدّ وقياس سمك لا تستطيع لمسه.
لا تستطيع وضع سمكة سلمون على ميزان كل يوم. فتقيسها المزارع بالكاميرات بدلًا من ذلك.
يضع المصنّفون نقاطًا مفصلية على السمكة — الرأس، الذيل، الزعانف — فيتعلّم النموذج قراءة الحجم من تلك النقاط. يستخدم إطار عمل بحري واحد على سمك الكوبيا أربع نقاط مفصلية: الرأس، الذيل، الزعنفة اليسرى، الزعنفة اليمنى. وتُبلّغ دراسة نقاط مفصلية منفصلة عن تقديرات طول سمك دقيقة بنحو ٩٧٪، في حدود سنتيمتر تقريبًا من الحقيقة الأساسية. ٦٢٦٣
مسار العمل نفسه، حيوان مختلف: بنية يصنّفها إنسان، يقيسها آلة.
الأحياء البرية: السلوك في البرّية، بلا طوق.
تتتبّع فرق الحفظ الحيوانات بالوضعية وحدها الآن — الشمبانزي والبونوبو في البرّية، وقطعان الفيلة كاملةً من لقطات الطائرات المسيّرة، والسلمون في أحواض البحث. تتيح أدوات مثل DeepLabCut للباحثين تصنيف نقاط مفصلية على بضع مئات من الإطارات، ثم تتبّع الوضعية عبر ساعات من الفيديو. ٦٤٦٥٦٦٦٧
بلا وسوم. بلا أطواق. مجرد معالم علّم إنسانٌ النموذج أن يجدها.
طريقة واحدة. من عدّاء إلى سمكة سلمون.
كل واحدة من هذه تبدأ بالطريقة نفسها: إنسانٌ يضع نقطة في مركز مفصل، أو ساق ثمرة، أو زعنفة.
ذلك هو تصنيف النقاط المفصلية في محرك التصنيف لدينا — نقاط مصنَّفة ملوّنة على صورة، ومعيار ذهبي مكتوب بشريًا كالإجابة الصحيحة، مُصدَّرة كـJSON قياسي. واحدة من ١٨٠ واجهة عبر ٧ وسائط، كلّها مباشرة.
الحيوان يتغيّر. والطريقة لا. البشر يعلّمون الآلة — وذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
مستعدّ لتعليمها أن ترى؟ احجز عرضًا على annota8.ai.
حين يختفي مفصل: جدول قرار الحجب
الحجب هو حيث تنحرف معظم مجموعات بيانات النقاط المفصلية بصمت. ساقٌ تختفي خلف الأخرى. يدٌ تذهب خلف الظهر. مصنّفٌ يخمّن — أو يتخطّى بلا اتّساق — يُعلّم النموذج ضجيجًا.
الحلّ قاعدة مكتوبة، تُطبَّق بالطريقة نفسها في كل مرة. COCO تمنحك العلم؛ وأنت تمنحها السياسة.
| المفصل… | اضبط v على | ضع (س، ص)؟ | لماذا |
|---|---|---|---|
| مرئي في الإطار | 2 | نعم — على المعلم | يتعلّم النموذج مثالًا واثقًا مرئيًا |
| محجوب (خلف جزء جسد آخر أو شيء) لكن يمكنك استنتاج موضعه | 1 | نعم — أفضل تقدير لموضعه المختفي | يُعلّم النموذج أن المفاصل موجودة حتى حين تختفي؛ ويُبقي الهيكل سليمًا |
| خارج الإطار / مقطوع (تقطعه حافّة الصورة) | 0 | لا — اضبط 0, 0 | لا شيء يُتعلَّم هنا؛ نقطة مخمَّنة خارج الإطار ضجيج محض |
| غائب حقًا (المعلم غير موجود — مثلًا بَتْر، أو جسم خاطئ) | 0 | لا — اضبط 0, 0 | المعلم غير موجود لهذه الحالة |
قاعدتان تجعلان هذا محكمًا:
قدّر المحجوب، ولا تخترع الغائب أبدًا. إن كانت ركبة خلف ساق، فأنت تعرف موضعها تقريبًا — صنّفها 1 وضع تقديرك. وإن كانت قدم خارج أسفل الإطار، فلا تعرف — صنّفها 0 واتركها عند الأصل. ٢٢٢٣
قرّر قبل أن تصنّف، ثم افرض. اكتب السياسة في الدليل مع صورة لكل صفّ. معالجة الحجب غير المتّسقة من أهدأ طرق تسميم مجموعة بيانات — وأصعبها تصحيحًا بعد التدريب.
هذه «جودة تدخل». لا تستطيع الآلة تمييز «زال» من «خلف شيء» إلا إذا أخبرها مصنّفوك بالفرق، بالطريقة نفسها، في كل مرة.
كيف تنال جودة في تصنيف النقاط المفصلية: قائمة تحقّق مجرّبة ميدانيًا
جودة تصنيف النقاط المفصلية تتلخّص في قاعدة واحدة: كل مصنّف يضع النقطة نفسها في الموضع نفسه، في كل مرة. حقّق ذلك، فيتعلّم النموذج بنية نظيفة. أهمله، فتُعلّم الآلة ضجيجك.
إليك قائمة التحقّق التي نُجريها.
١. ثبّت الأنطولوجيا أولًا. قرّر بالضبط أي النقاط موجودة وما يعنيه كلٌّ منها قبل أن يصنّف أحد. معيار وضعية الجسم هو ١٧ نقطة في COCO — الأنف، والعينان، والأذنان، والكتفان، والمرفقان، والمعصمان، والوركان، والركبتان، والكاحلان. وتحتاج الأيدي والوجوه والأشياء أنطولوجياتها الخاصة. اختر واحدة واكتبها. ٦٩
٢. اكتب الدليل، بالصور. «كتف» ليس تعليمة. «مركز مفصل الكتف العضدي، حتى حين تُرفع الذراع» هو التعليمة. عرّف كل معلم تشريحيًا. اعرض مثالًا صحيحًا وآخر خاطئًا لكل نقطة.
٣. اطلب دقة مركز المفصل. النقاط المفصلية ليست «قرب المرفق». إنها على مركز المفصل. نقطة تنحرف بضع بكسلات في كل مرة تصير نموذجًا يخمّن. في محرك التصنيف لدينا، يضع المصنّفون نقاطًا ملوّنة — كتف، مرفق، معصم، ركبة — بدقة مركز المفصل على لوحة الصورة.
٤. اضبط سياسة حجب صريحة. الصور الحقيقية تُخفي أشياء. تُرمّز COCO هذا بعلم رؤية لكل نقطة: v=0 غير مصنَّفة، v=1 مصنَّفة لكن غير مرئية (محجوبة)، v=2 مصنَّفة ومرئية. قرّر قاعدتك مسبقًا — أيقدّر المصنّفون ركبة مختفية، أم يتخطّونها؟ ثم افرضها. معالجة الحجب غير المتّسقة من أهدأ طرق تسميم مجموعة بيانات. ٦٨
٥. عالِج القطع وتعدّد الأجسام. ساق تقطعها حافّة الإطار. لاعبان متداخلان. على دليلك أن يقول ما العمل: أي جسم يُصنَّف، وكيف تُعالَج النقاط خارج الإطار، وكيف تُبقي الهياكل من تشابك أسلاكها. الغموض هنا يتضاعف سريعًا.
٦. قِس اتفاق المصنّفين — ثم احكم. دع عدّة أشخاص يصنّفون الصور نفسها. قارن. والتسامح المعياري مكاني: كم يبتعد مصنّفان، بالبكسل، عند المفصل نفسه. حين يهبط الاتفاق على مفصل بعينه، فدليلك غامض، لا مصنّفوك. أصلِح الدليل، وأعِد التدريب، وأعِد القياس. أرسل الخلافات الحقيقية إلى حَكَمٍ لإجابة ذهبية. ٧٠
٧. ابنِ معيارًا ذهبيًا. مجموعة «إجابة صحيحة» مكتوبة باليد هي كيف تُقيّم الجميع مقابل الحقيقة، لا مقابل بعضهم. وفي محركنا تعمل أيضًا كمرجع للتصنيف المسبق: نموذج من الأعلى للأسفل مثل ViTPose، مقترنًا بكاشف أشخاص مثل YOLO، يقترح نقاطًا، يصحّحها إنسان، وتلتقط المجموعة الذهبية الانحراف. ٧١
إليك الجزء الذي تستهين به معظم الفرق. مقياس الدقة الخاصّ بـCOCO، أي OKS (تشابه النقاط المفصلية للأجسام)، يقيس الخطأ المسموح على كل نقطة بمقدار اختلاف المصنّفين البشريين على تلك النقطة أصلًا. قاست COCO ذلك الانتشار عبر ٥٬٠٠٠ صورة مصنَّفة بتكرار — فتنال نقطة محدّدة جيدًا كالعين تسامحًا أضيق من نقطة غامضة كالورك. المقياس مبني حرفيًا من اتّساق البشر. النقاط المُهمَلة لا تخفض تصنيفًا واحدًا فحسب — بل توسّع السقف الذي يُقاس به المجال كلّه. ٦٨٦٩
لهذا ينعكس انضباط التصنيف مباشرةً في المقياس الذي يُبلّغ عنه نموذجك. كيف تضع نقطة وتصنّفها يحسم الـOKS الذي يستطيع تحقيقه.
نموذج الوضعية يتعلّم الهيكل الذي ترسمه. بضع نقاط موضوعة بسوء، مكرّرةً عبر مجموعة بيانات، فيتعلّم النموذج المفصل الخاطئ. جودة تدخل، جودة تخرج.
البشر يعلّمون الآلة. ذكاؤك الاصطناعي ليس أفضل ممّن علّموه.
الكلفة والإنتاجية: الميكانيكا الصادقة
تصنيف النقاط المفصلية مكلِف لأن شخصًا يضع كل نقطة، على كل حالة، على كل إطار. والفيديو يزيده سوءًا — مقطع ٣٠ ثانية بمعدّل ٣٠ إطارًا في الثانية يساوي ٩٠٠ إطار. وإليك كيف تُبقي الفرق الفاتورة منخفضة فعلًا دون تسميم البيانات.
التصنيف المسبق بمساعدة النموذج. يضع نموذج وضعية (YOLO-pose أو ViTPose أو OpenPose أو MediaPipe) هيكلًا أوّليًا، ويصحّحه الإنسان بدل وضعه من الصفر. والتصحيح أسرع من التأليف. والمصيدة: نقطة آلية واثقة لكن خاطئة يسهل ختمها بلا تدقيق، فمرحلة المراجعة البشرية ليست اختيارية. ٢٧٧١
استيفاء الإطارات للفيديو. صنّف النقاط المفصلية على الإطارات المفتاحية، ودع الأداة تستوفي المفاصل عبر الإطارات بينها، ثم افحص عشوائيًا وصحّح حيث تكسر الحركة الاستيفاء. تدفع مقابل جزء من الإطارات وتراجع الباقي.
اتّساق المناظر المتعدّدة. حين تملك كاميرات متزامنة، مفصل مصنَّف في منظر يقيّد موضعه في الباقية. مرور واحد متأنٍّ ينتشر.
المراجعة المرحلية. صنّف ← مراجعة الأقران ← حكم الخلافات ← تدقيق المعيار الذهبي. كل مرحلة تكلّف وقتًا لكنها تلتقط الأخطاء التي تكلّف أكثر بكثير بعد التدريب.
إليك الرقم الذي يؤطّر كل ذلك: عبر صناعة تصنيف البيانات، يلتهم الإهدار وإعادة العمل نحو ٦٠٪ من الميزانية. الشخص الخطأ يصنّفه، فيعود، فتُعيده — ومعظم الإنفاق لم يلمس تصنيفًا صحيحًا قطّ. تلك ضريبة سوء العملية، لا سوء الناس.
تلك الـ٦٠٪ هي بالضبط الإهدار الذي بنينا محرك التصنيف من Annota8 لخفضه: تصنيف مسبق لتقليص المرور الأول، ومعيار ذهبي لالتقاط الانحراف مبكرًا، وفحوص اتفاق كي تحدث إعادة العمل قبل التدريب لا بعده. الآلة تقترح، والإنسان يقرّر، والمجموعة الذهبية تُبقي كليهما صادقَين.
جودة تدخل، جودة تخرج. احجز عرضًا على annota8.ai.
أسئلة شائعة
تصنيف النقاط المفصلية هو وضع معالم دقيقة (كالمفاصل أو نقاط الوجه) على الصور والفيديو كإحداثيات س وص، كي يتعلّم النموذج البنية والوضعية. إنسانٌ يضع كل نقطة، فيبني الحقيقة الأساسية التي ينسخها الذكاء الاصطناعي. الأمثلة هي بيانات التدريب. جودة تدخل، جودة تخرج.
تصنيف النقاط المفصلية هو عمل التصنيف البشري الذي يصنع معالم الحقيقة الأساسية؛ وتقدير الوضعية هو النموذج الذي يتعلّم أن يتنبأ بتلك المعالم وحده. أحدهما يُعلّم، والآخر يُكرّر. النموذج لا يفوق جودة النقاط التي وضعها البشر، ولهذا تحسم جودة التصنيف دقة الوضعية.
تستخدم COCO ١٧ نقطة جسمية لكل شخص: الأنف، والعينان اليسرى واليمنى، والأذنان، والكتفان، والمرفقان، والمعصمان، والوركان، والركبتان، والكاحلان. تُخزَّن كل نقطة كثلاث قيم (س، ص، الرؤية)، حيث الرؤية ٠ (غير مصنَّفة)، أو ١ (مصنَّفة لكن محجوبة)، أو ٢ (مصنَّفة ومرئية).
تكتشف MediaPipe ٢١ معلمًا لكل يد، و٣٣ معلم وضعية للجسم، و٤٦٨ معلم شبكة وجه (٤٧٨ عند إضافة نقاط القزحية). ومجتمعةً في Holistic، يبلغ ذلك ٥٤٣ معلمًا لكل شخص. توجّه هذه المخططات كيف يعرّف المصنّفون البشريون النقاط ويصنّفونها عند بناء بيانات تدريب مطابقة.
علم الرؤية في COCO قيمة مرفقة بكل نقطة مفصلية: ٠ يعني غير مصنَّفة، و١ يعني مصنَّفة لكن محجوبة (مختفية خلف شيء)، و٢ يعني مصنَّفة ومرئية. يخبر النموذج بأي النقاط يثق وأي المواضع استنتجها إنسان، فيُعالَج الحجب على نحو صحيح.
صنّف النقطة المحجوبة بالرؤية ١، واضعًا إياها في أفضل موضع مُقدَّر رغم أنها مختفية. تظل النقطة مصنَّفة؛ ويخبر العلم النموذج أن إنسانًا استنتجها. هذا يُعلّم الشبكة أن تتنبأ بالمفاصل خلف الملابس أو الأشياء أو الأشخاص الآخرين. الحجب هو القاعدة في اللقطات الواقعية، لا الاستثناء.
المربّع المحيط يقول إن شيئًا موجود في مكان ما من الإطار؛ أما تصنيف النقاط المفصلية فيصف بنيته الداخلية، مفصلًا بمفصل. المربّعات تلتقط الامتداد، والنقاط المفصلية تلتقط البنية والوضعية. للحركة أو الإيماءة أو الميكانيكا الحيوية، تحتاج إلى النقاط والهيكل الذي يربطها، لا مجرد مستطيل حول الجسم.
OKS (تشابه النقاط المفصلية للأجسام) يقيس مدى قرب النقاط المتوقَّعة من الحقيقة الأساسية المُصنَّفة بشريًا، بنتيجة بين ٠ و١. يُسوّي الخطأ بحجم الجسم ويرجّح النقاط بمدى دقة تحديد موضع كلٍّ منها. تستخدم COCO الـOKS لحساب متوسط الدقة للوضعية، تمامًا كما يعمل IoU في الكشف.
تستخدم MPII Human Pose ١٦ نقطة جسمية لكل شخص، أي أقل بواحدة من ١٧ في COCO. تعرّف المعايير المختلفة هياكل مختلفة، فالمخطط الصحيح يتبع مهمّتك. قبل التصنيف، ثبّت تعريف النقطة المفصلية وترتيبها. الهيكل المتّسق المُوثَّق هو ما يبقي المصنّفين والنموذج المُدرَّب متّفقين.
يضيف الفيديو الاستمرارية: يتتبّع المصنّفون النقاط نفسها عبر الإطارات كي يبقى الهيكل سلسًا ومتّسقًا. الاستيفاء بين الإطارات المفتاحية والانتشار بمساعدة النموذج يقلّلان العمل اليدوي، لكن يظل البشر يتحقّقون. الأجزاء الصعبة هي ضبابية الحركة والحجب وتداخل الأشخاص وحركة الكاميرا، وهي بالضبط حيث يكسب المصنّف المتأني الدقة.
تحليلات الرياضة، والرعاية الصحية والعلاج الطبيعي، واللياقة، والروبوتات، والواقع المعزّز والافتراضي، والسلامة في مكان العمل، وتتبّع الحيوانات أو الأحياء البرية، جميعها تعتمد على تصنيف النقاط المفصلية. وكلٌّ منها يقيس الحركة، من زوايا مفاصل ضربة الغولف إلى مدى حركة المريض. كل واحد من تلك النماذج علّمه البشر أولًا بوضع النقاط باليد.
تُقاس الجودة باتفاق المصنّفين فيما بينهم (عدّة مصنّفين على الإطارات نفسها)، وعتبات التسامح بالبكسل، والفحوص العشوائية من المراجع للنقاط المحجوبة أو الضبابية. تختبر الفرق غالبًا المصنّفين أمام تصنيفات ذهبية وتُكرّر حصةً من العمل لإشارات اتفاق مستمرة. ضبط الجودة الدقيق هو ما يفصل الحقيقة الأساسية القابلة للاستخدام عن البيانات المشوّشة.
قد يبدأ التسعير الصناعي المنشور لتصنيف النقاط المفصلية من نحو ٠٫٠١٥ دولار لكل جسم٧٣، لكن الكلفة الحقيقية تتوقف على عدد النقاط، والحجب، وطول الفيديو، وسقف الدقة. عمل الميكانيكا الحيوية الطبية أو الرياضية يكلّف أكثر لأن التسامحات أضيق. أرخص تصنيف نادرًا ما يكون الصحيح؛ فإعادة العمل تمحو أي توفير سريعًا.
نعم. يشمل محرك التصنيف من Annota8 أداة نقاط مفصلية مباشرة، ضمن ١٨٠ واجهة عبر ٧ وسائط، فتضع الفرق النقاط، وتبني الهياكل، وتعالج الرؤية على الصور والفيديو. ويساعد مساعدٌ ذكي موصول ببيانات تصنيفك. ويبقى البشر في المقدمة. احجز عرضًا على annota8.ai.
الهيكل الجيد له قائمة نقاط ثابتة، وترتيب فهارس مستقر، وقواعد واضحة للحجب والحالات الحدّية، موثّقة قبل بدء التصنيف. الاتّساق بين المصنّفين يهمّ أكثر من العدد بالضبط. يتعلّم النموذج ما يعرّفه البشر، فالمخطط الدقيق المُعلَّم جيدًا هو ما يُنتج نموذج وضعية دقيقًا موثوقًا.
المراجع
- COCO — Keypoint Detection Task. https://cocodataset.org/#keypoints-2020 — النقاط المفصلية في COCO مهمة مستقلة إلى جانب الكشف والتقطيع؛ معيار جسم الإنسان ذو الـ١٧ نقطة برؤية لكل نقطة وروابط هيكل.
- COCO Keypoints format — CVAT docs. https://docs.cvat.ai/docs/dataset_management/formats/format-coco-keypoints/ — صيغة COCO للنقاط المفصلية: كل نقطة = (x, y, v) بـ v∈{0,1,2}؛ حقل «skeleton» يعرّف الحوافّ الرابطة بين النقاط؛ ١٧ نقطة.
- COCO-Pose Dataset — Ultralytics Docs. https://docs.ultralytics.com/datasets/pose/coco/ — COCO-Pose تستخدم ١٧ نقطة لكل شخص؛ kpt_shape [17,3] = x, y, الرؤية؛ قائمة مفاصل مسمّاة؛ JSON قابل للاستهلاك بخطوط التدريب.
- MPII Human Pose Dataset — Max Planck Institute for Informatics. https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/software-and-datasets/mpii-human-pose-dataset — تصنّف MPII ١٦ مفصلًا جسميًا لكل شخص بعلم رؤية؛ نحو ٢٥ ألف صورة، و٤٠ ألف+ شخص (Andriluka et al., CVPR 2014).
- OpenPose BODY_25 model — CMU Perceptual Computing Lab. https://github.com/CMU-Perceptual-Computing-Lab/openpose/tree/master/models/pose/body_25 — BODY_25 هو نموذج OpenPose الافتراضي ذو الـ٢٥ نقطة للجسم والقدم (يشمل نقاط القدم).
- MediaPipe Pose — Google AI Edge. https://github.com/google-ai-edge/mediapipe/blob/master/docs/solutions/pose.md — تستنتج MediaPipe Pose ٣٣ معلمًا ثلاثي الأبعاد؛ إحداثيات مُسوّاة إلى [0,1] بعرض الصورة (x) وارتفاعها (y).
- MediaPipe Hands — Google AI Edge. https://github.com/google-ai-edge/mediapipe/blob/master/docs/solutions/hands.md — تستنتج MediaPipe Hands ٢١ معلمًا ثلاثي الأبعاد لكل يد من إطار واحد؛ نحو ٣٠ ألف صورة واقعية مصنَّفة يدويًا بـ٢١ إحداثيًا ثلاثي الأبعاد كحقيقة أساسية.
- MediaPipe Face Mesh — official docs (readthedocs mirror). https://mediapipe.readthedocs.io/en/latest/solutions/face_mesh.html — تُنتج Face Mesh ٤٦٨ معلمًا افتراضيًا؛ و٤٧٨ بـ refine_landmarks=True (تضيف ١٠ نقاط قزحية، ٥ لكل عين).
- COCO Dataset — Ultralytics Docs. https://docs.ultralytics.com/datasets/detect/coco/ — تدعم COCO كشف الأجسام (المربّعات)، والتقطيع (الأقنعة)، وكشف النقاط المفصلية — ثلاث مهام تصنيف متمايزة: الموقع مقابل الشكل مقابل البنية.
- Keypoint Annotation: Labeling Data With Keypoints & Skeletons — V7. https://www.v7labs.com/blog/keypoint-annotation-guide — تصنيف النقاط المفصلية = وضع نقاط معالم مربوطة بحوافّ هيكل؛ تُستخدم النقطة المفصلية/الوضعية/المعلم بالتبادل؛ يلتقط البنية/الوضعية مقابل الموقع (المربّع) والشكل (التقطيع).
- COCO Dataset — Data Format (keypoints). https://cocodataset.org/#format-data — يخزّن تصنيف COCO كل نقطة كـ [x, y, v]؛ v=0 غير مصنَّفة، v=1 مصنَّفة لكن غير مرئية، v=2 مصنَّفة ومرئية؛ فئة الشخص تعرّف ١٧ نقطة.
- COCO-WholeBody data_format.md. https://github.com/jin-s13/COCO-WholeBody/blob/master/data_format.md — حقل نقاط الجسم مصفوفة بطول 3*17 (x, y, v)؛ يعدّد الأسماء الـ١٧؛ دلالات v=0/1/2. تضيف COCO-WholeBody الوجه (٦٨) واليدين (٤٢) والقدمين (٦) بمجموع ١٣٣.
- Lin et al., Microsoft COCO: Common Objects in Context (ECCV 2014). https://arxiv.org/abs/1405.0312 — منشأ مجموعة COCO وخطّ تصنيفها البشري لكل حالة؛ يرسّخ COCO مرجعًا معياريًا لتصنيف الحقيقة الأساسية للنقاط المفصلية/المعالم.
- OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields (Cao et al.). https://arxiv.org/abs/1812.08008 — OpenPose نظام تأسيسي مفتوح المصدر من الأسفل للأعلى لتقدير وضعية ثنائية الأبعاد متعدّدة الأشخاص (نقاط الجسم/القدم/اليد/الوجه).
- Deep High-Resolution Representation Learning for Human Pose Estimation (HRNet, Sun et al., CVPR 2019). https://arxiv.org/abs/1902.09212 — HRNet نموذج وضعية بشرية راسخ مدرَّب على حقيقة أساسية مصنَّفة يدويًا (COCO/MPII)؛ التعلّم الخاضع للإشراف يستنسخ النقاط الموضوعة بشريًا.
- ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation (Xu et al., NeurIPS 2022). https://arxiv.org/abs/2204.12484 — ViTPose نموذج تقدير وضعية راسخ قائم على محوّل الرؤية.
- Pose Estimation — Ultralytics Docs. https://docs.ultralytics.com/tasks/pose/ — YOLO-pose (YOLOv8-Pose / YOLO11-Pose) نموذج وضعية بمرور واحد؛ النموذج البشري الافتراضي يستخدم نقاط COCO الـ١٧.
- Pervasive Label Errors in Test Sets Destabilize ML Benchmarks (Northcutt, Athalye, Mueller). https://arxiv.org/abs/2103.14749 — أخطاء التصنيف في بيانات الاختبار تبلغ ≥3.3% في المتوسط (>6% في تحقّق ImageNet) وتُزعزع تقييم النماذج — يدعم «جودة تدخل، جودة تخرج» / انتشار الخطأ.
- cocoapi Issue #130 — 'making own COCO data: what does visible mean?'. https://github.com/cocodataset/cocoapi/issues/130 — يؤكّد عرف v=0 (غير مصنَّفة، x=y=0)، v=1 (مصنَّفة، محجوبة)، v=2 (مصنَّفة، مرئية)، وأن المصنّفين يصنّفون النقاط المحجوبة بدل إسقاطها. JSON من COCO-Pose يدخل خطوط التدريب.
- COCO format — CVAT documentation. https://docs.cvat.ai/docs/dataset_management/formats/format-coco/ — تخزّن COCO التصنيفات كـ JSON بحقول bbox (الموقع) وsegmentation (الشكل) وkeypoints منفصلة؛ نقاط الشخص = ١٧ كلٌّ بـ x,y + علم رؤية v=0/1/2؛ التصدير JSON.
- Create COCO Annotations From Scratch — Immersive Limit. https://www.immersivelimit.com/tutorials/create-coco-annotations-from-scratch — جولة في مخطط COCO JSON (images, annotations, categories؛ bbox, segmentation, keypoints) ومعالجة علم الرؤية للنقاط المحجوبة مقابل خارج الإطار.
- On-device, Real-time Body Pose Tracking with MediaPipe BlazePose — Google Research. https://research.google/blog/on-device-real-time-body-pose-tracking-with-mediapipe-blazepose/ — تستخدم MediaPipe Pose بنية BlazePose ذات الـ٣٣ نقطة، وهي مجموعة فائقة لنقاط COCO الـ١٧.
- MediaPipe Hands — official docs (readthedocs mirror). https://mediapipe.readthedocs.io/en/latest/solutions/hands.html — تستنتج MediaPipe Hands ٢١ معلمًا ثلاثي الأبعاد لكل يد من إطار واحد.
- MediaPipe Face Mesh documentation — Google AI Edge. https://github.com/google-ai-edge/mediapipe/blob/master/docs/solutions/face_mesh.md — تقدّر MediaPipe Face Mesh ٤٦٨ معلم وجه ثلاثي الأبعاد في الزمن الحقيقي من كاميرا واحدة بلا مستشعر عمق؛ x,y مُسوّاة إلى [0,1].
- Maji et al., YOLO-Pose: Multi-Person Pose Estimation with OKS Loss (CVPRW 2022). https://arxiv.org/abs/2204.06806 — يكشف YOLO-pose مربّعات الأشخاص والوضعيات ثنائية الأبعاد (النقاط المفصلية) معًا في مرور أمامي واحد — يدعم ادّعاء «الهيكل الأوّلي» للتصنيف المسبق.
- VideoRun2D: Cost-Effective Markerless Motion Capture for Sprint Biomechanics. https://arxiv.org/abs/2409.10175 — ميكانيكا حيوية للعَدْو بلا علامات من فيديو قياسي (قائمة على MoveNet) تُبلّغ عن أخطاء زاوية مفصلية ٣٫٢–٥٫٥ درجة مقابل المرجع القائم على العلامات عبر الجذع والورك والركبة.
- Internet-of-Things-Enabled Markerless Running Gait Assessment from a Single Smartphone Camera (Sensors, MDPI). https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9866353/ — تقييم مشية العَدْو بلا علامات من كاميرا هاتف واحدة (BlazePose، ٣٣ نقطة) مُتحقَّق منه مقابل Vicon — صالح لمنع الإصابات/البيئات قليلة الموارد.
- Making Sport Fairer with Accurate Event Detection — Hawk-Eye Innovations. https://www.hawkeyeinnovations.com/news/4227979/making-sport-fairer-with-accurate-event-detection-the-future-of-officiating-via-skeletal-tracking — يتتبّع SkeleTRACK من Hawk-Eye ٢٩ نقطة هيكلية لكل لاعب؛ تسلل شبه آلي (كرة + تتبّع هيكلي) منشور في كرة القدم الاحترافية الكبرى منذ ٢٠٢٢.
- NBA to use Hawk-Eye tracking system to follow players, ball — ESPN. https://www.espn.com/nba/story/_/id/35818363/nba-use-hawk-eye-tracking-system-follow-players-ball — اعتمد الـ NBA تتبّع Hawk-Eye البصري ثلاثي الأبعاد للوضعية من Sony بدءًا من موسم 2023-24 لتتبّع كل لاعب والكرة.
- Real-time driver monitoring system with facial landmark-based eye closure detection and head pose recognition (Scientific Reports 2023). https://pmc.ncbi.nlm.nih.gov/articles/PMC10600215/ — يتتبّع نظام مراقبة السائق رأس السائق وعينيه عبر تقدير معالم الوجه، مع وحدتي وضعية الرأس (عدم الانتباه) وانغلاق العين (النعاس).
- Driver Drowsiness Detection Using EAR, MAR, and Head Pose Estimation (Springer). https://link.springer.com/chapter/10.1007/978-981-16-5987-4_63 — يستخدم كشف النعاس نسبة عرض العين من معالم الوجه (الإغلاق الأطول يخفض EAR)، والتثاؤب عبر نسبة عرض الفم، والتشتت من وضعية الرأس.
- Occupant Status Monitoring — Euro NCAP (ratings explained). https://www.euroncap.com/en/car-safety/the-ratings-explained/safety-assist/occupant-status-monitoring/ — يُقيّم Euro NCAP مراقبة حالة السائق المباشرة ضمن مساعدة السلامة؛ يقيس التشتت والإرهاق/النعاس وعدم الاستجابة من اتجاه النظر ووضعية الرأس.
- Euro NCAP Assessment Protocol — SA Safe Driving v10.4. https://www.euroncap.com/media/80158/euro-ncap-assessment-protocol-sa-safe-driving-v104.pdf — بروتوكول مراقبة حالة السائق المباشرة (منذ يناير ٢٠٢٣): كشف التشتت والنعاس/الإرهاق وعدم الاستجابة من اتجاه النظر ووضعية الرأس، شاملًا الإرهاق عند سرعة الطرق السريعة.
- European NCAP Program Developments to Address Driver Distraction, Drowsiness and Sudden Sickness (Frontiers in Neuroergonomics). https://www.frontiersin.org/journals/neuroergonomics/articles/10.3389/fnrgo.2021.786674/full — يدفع Euro NCAP نحو مراقبة حالة السائق المباشرة القائمة على الكاميرا؛ ويُعدّ الاستنتاج غير المباشر/القائم على المقود وحده غير كافٍ للائتمان الكامل.
- What is the COCO Keypoint Annotation Format? — Roboflow. https://roboflow.com/formats/coco-keypoint — تخزّن COCO النقاط كمصفوفة بطول 3k من ثلاثيات x,y,v إضافةً إلى num_keypoints؛ تعرّف الفئات قائمة أسماء وقائمة أزواج حوافّ «skeleton» (مثل [16,14])؛ تُعيد ذكر v=0/1/2.
- Comparing Controller With the Hand Gestures Pinch and Grab for Picking Up and Placing Virtual Objects (arXiv). https://arxiv.org/pdf/2202.10964 — إيماءتا القرص والقبض تخدمان كإدخال بلا متحكّم لمعالجة الأجسام الافتراضية في الواقع الافتراضي.
- Keypoint Annotation vs. Bounding Box: What's the Difference?. https://www.infosearchbpo.com/bpo-news/keypoint-annotation-vs-bounding-box-whats-the-difference/ — المربّعات تعطي موقع الجسم (x,y,w,h)؛ والنقاط المفصلية تلتقط نقاط البنية/الملامح؛ والتقطيع يلتقط شكل البكسل الدقيق — التصنيف الثلاثي.
- Impact of Vision 2030 on traffic safety in Saudi Arabia (Int. J. Pediatrics and Adolescent Medicine). https://pmc.ncbi.nlm.nih.gov/articles/PMC6363273/ — حوادث الطرق سبب رئيسي للوفاة في السعودية؛ تستهدف رؤية ٢٠٣٠ أقل من ١٠ وفيات طرق لكل ١٠٠٬٠٠٠ بحلول ٢٠٣٠.
- Reducing Road Crash Deaths in the Kingdom of Saudi Arabia — WHO. https://www.who.int/news/item/20-06-2023-reducing-road-crash-deaths-in-the-kingdom-of-saudi-arabia — يؤكّد حجم وفيات حوادث الطرق في السعودية والدفع الوطني/رؤية ٢٠٣٠ لخفض وفيات الطرق.
- Gesture Recognition: How Touchless Control Works — Ultralytics. https://www.ultralytics.com/blog/vision-ai-enables-touch-free-gesture-recognition-technology — نقاط اليد المفصلية (أطراف الأصابع/المفاصل) تشغّل التعرّف على الإيماءات للواقع المعزّز/الافتراضي والواجهات بلا لمس — قرص للتكبير/القبض، تمرير للتنقّل، إشارة للاختيار.
- Facial landmarks with dlib, OpenCV, and Python — PyImageSearch. https://pyimagesearch.com/2017/04/03/facial-landmarks-dlib-opencv-python/ — يقدّر كاشف dlib المدرَّب مسبقًا ٦٨ نقطة معالم وجه (x,y) عبر العينين والحاجبين والأنف والفم وخطّ الفك؛ مدرَّب على مجموعة iBUG 300-W.
- dlib C++ Library — face_landmark_detection.py. https://dlib.net/face_landmark_detection.py.html — مثال dlib الرسمي باستخدام مُتنبّئ الشكل ذي الـ٦٨ نقطة لكشف معالم الوجه.
- MediaPipe Face Mesh documentation (google-ai-edge/mediapipe). https://github.com/google-ai-edge/mediapipe/blob/master/docs/solutions/face_mesh.md — تقدّر MediaPipe Face Mesh ٤٦٨ معلم وجه ثلاثي الأبعاد من كاميرا واحدة بلا مستشعر عمق مخصّص.
- Facial Action Coding System — Wikipedia. https://en.wikipedia.org/wiki/Facial_Action_Coding_System — FACS، الذي طوّره بول إكمان ووالاس ف. فريزن ونُشِر عام ١٩٧٨، يفكّك تعبيرات الوجه إلى وحدات حركة (حركات عضلات الوجه).
- Facial Action Coding System — Paul Ekman Group. https://www.paulekman.com/facial-action-coding-system/ — يرمّز FACS (إكمان وفريزن) تعبيرات الوجه كوحدات حركة تمثّل حركات عضلات الوجه؛ يدعم تحليل تعبير الوجه/المشاعر.
- ISO/IEC 30107-3:2017 — Biometric presentation attack detection — Part 3: Testing and reporting. https://cdn.standards.iteh.ai/samples/67381/653843ba232d403998c64a4aaad6d2cc/ISO-IEC-30107-3-2017.pdf — معيار دولي يحدّد منهجية اختبار كشف هجمات العرض ومقاييسه (APCER, BPCER) — تمييز وجه حيّ من انتحال كصورة مطبوعة أو إعادة عرض على شاشة.
- The ISO/IEC 30107-3 standard for testing of Presentation Attack Detection — NIST/IBPC. https://www.nist.gov/system/files/documents/2020/09/15/12_buschthieme-ibpc-pad-160504.pdf — يؤكّد أن ISO/IEC 30107-3 يحكم اختبار كشف هجمات العرض والتبليغ عنه ويعرّف مقياسي APCER/BPCER.
- Video-based Surgical Tool-tip and Keypoint Tracking using Multi-frame Context-driven Deep Learning Models (arXiv:2501.18361). https://arxiv.org/abs/2501.18361 — نماذج تعلّم عميق تتتبّع نقاط طرف الأداة الجراحية وقاعدتها في الفيديو؛ صعبة بسبب تغيّر الإضاءة والحجب وضبابية الحركة وتمفصل الأدوات.
- ToolTipNet: A Segmentation-Driven Deep Learning Baseline for Surgical Instrument Tip Detection (arXiv:2504.09700). https://arxiv.org/html/2504.09700v1 — كشف تعلّم عميق لأطراف الأدوات الجراحية الصغيرة على الفيديو الجراحي؛ يؤكّد أن أطراف الأدوات صغيرة وصعبة التحديد.
- Deep Learning Techniques for Automatic Lateral X-ray Cephalometric Landmark Detection: Is the Problem Solved? (arXiv:2409.15834). https://arxiv.org/html/2409.15834v1 — يصنّف التحليل القياسي للجمجمة معالم على أشعّة جانبية للجمجمة/الأسنان لتخطيط التقويم؛ نماذج تعلّم عميق تكشف المعالم آليًا، مدرَّبة على أشعّة صنّفها طبيب.
- A fully deep learning model for the automatic identification of cephalometric landmarks (PMC8479429). https://pmc.ncbi.nlm.nih.gov/articles/PMC8479429/ — نموذج تعلّم عميق يحدّد المعالم القياسية للجمجمة آليًا على الصور الجانبية، مدرَّب على أشعّة صنّفها أطبّاء.
- Validity of AI-Driven Markerless Motion Capture for Spatiotemporal Gait Analysis in Stroke Survivors (Sensors 2025). https://pmc.ncbi.nlm.nih.gov/articles/PMC12431465/ — تحليل مشية مكاني-زمني بالتقاط حركة بلا علامات قائم على الفيديو مُتحقَّق منه لدى ١٩ ناجيًا من السكتة مقابل ممشى مرجعي مُجهّز، بصلاحية جيدة إلى ممتازة لمعظم معاملات المشية.
- Validity of AI-based markerless motion capture for clinical gait analysis in healthy adults and adults with Parkinson's disease (J Biomechanics 2023). https://www.sciencedirect.com/science/article/abs/pii/S0021929023002142 — معاملات مشية مكانية-زمنية بالتقاط حركة بلا علامات قائم على الذكاء الاصطناعي مُتحقَّق منها لدى بالغين مصابين بالشلل الرعّاش مقابل مرجع قائم على العلامات.
- Video-Based Pose Estimation for Gait Analysis in Stroke Survivors during Clinical Assessments (PMC8832219, Digital Biomarkers). https://pmc.ncbi.nlm.nih.gov/articles/PMC8832219/ — تقدير وضعية بلا علامات قائم على الفيديو (DeepLabCut) يتتبّع نقاط الجسم (الورك، الركبة، الكاحل، العقب، إصبع القدم) من فيديو كاميرا واحدة لتقدير معاملات المشية لدى مرضى السكتة.
- Keypoint Detection and 3D Localization Method for Ridge-Cultivated Strawberry Harvesting Robots (MDPI Agriculture, 2025). https://www.mdpi.com/2077-0472/15/4/372 — مجموعة نقاط مفصلية للفراولة تصنّف خمس نقاط لكل ثمرة (نقطة القطف، أعلى، أسفل، نقطتا الإمساك اليسرى واليمنى) لتخطيط مسار الأداة الطرفية.
- Modular autonomous strawberry picking robotic system (Parsa et al., Journal of Field Robotics, 2024 / Robofruit). https://onlinelibrary.wiley.com/doi/full/10.1002/rob.22229 — يؤكّد مخطط الخمس نقاط للفراولة (نقطة القطف، أعلى، أسفل، نقطتا الإمساك اليسرى واليمنى) مع تصنيفات القابلية للقطف على مجموعة بيوت زجاجية.
- Strawberry Detection and Ripeness Classification Using YOLOv8+ Model and Image Processing (MDPI Agriculture, 2024). https://www.mdpi.com/2077-0472/14/5/751 — تُصنَّف درجة نضج الفراولة باللون، من غير الناضجة (أبيض/أخضر) عبر نصف الناضجة إلى تامّة النضج (أحمر).
- Deep learning pose estimation for multi-cattle lameness detection (Barney et al., Scientific Reports, 2023). https://www.nature.com/articles/s41598-023-31297-1 — يُخرج Mask-RCNN ٥ نقاط لتقوّس الظهر و٢ لوضعية الرأس (١٥ نقطة تشريحية مصنَّفة)؛ تحليل الوضعية/المشية بدقّة ٩٤–١٠٠٪، مُقيّمة بمصنّفي حركة معتمَدين.
- Intelligent Deep Learning and Keypoint Tracking-Based Detection of Lameness in Dairy Cows (MDPI Veterinary Sciences, 2025). https://pmc.ncbi.nlm.nih.gov/articles/PMC11946227/ — تتبّع نقاط مفصلية قائم على DeepLabCut (الرأس، الظهر، أربع أقدام) لعَرَج الأبقار يبلغ نحو ٩٠٪ دقّة (نحو ٨٧٪ بالانحدار اللوجستي في عمل مرتبط) — نطاق أواخر الثمانينيات إلى التسعينيات.
- Fish keypoint detection for offshore aquaculture: a robust deep learning approach with PCA-based shape constraint (Frontiers in Marine Science, 2025). https://www.frontiersin.org/journals/marine-science/articles/10.3389/fmars.2025.1619457/full — إطار عمل بحري لسمك الكوبيا يكشف أربع نقاط مفصلية — الرأس، الزعنفة اليسرى، الذيل، الزعنفة اليمنى.
- A review of deep learning-based stereo vision techniques for fish phenotype and behavioral analysis in aquaculture (Artificial Intelligence Review, Springer, 2024). https://link.springer.com/article/10.1007/s10462-024-10960-7 — يوثّق طريقة نقاط مفصلية (معالم طرف الأنف ومنتصف الذيل، معايرة ستيريو) تحقّق نحو ٩٧٪ دقّة لطول السمك في حدود ±1.15 سم.
- DeepWild: Application of DeepLabCut for behaviour tracking in wild chimpanzees and bonobos (Wiltshire et al., Journal of Animal Ecology, 2023). https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/1365-2656.13932 — DeepLabCut مدرَّب على فيديو محمول لتقدير وضعية متعدّدة الحيوانات/تتبّع سلوك الشمبانزي والبونوبو في البرّية بلا وسوم أو أطواق.
- Whole-Herd Elephant Pose Estimation from Drone Data for Collective Behavior Analysis (McNutt, Zhang et al., 2024). https://arxiv.org/abs/2411.00196 — تقدير وضعية (DeepLabCut، YOLO-NAS-Pose) يكشف نقاطًا مفصلية (الرأس، العمود، الأذنان) لقطعان فيلة كاملة من لقطات طائرات مسيّرة — سلوك الأحياء البرية بلا وسوم مادية.
- Applying deep learning and the ecological home range concept to document spatial distribution of Atlantic salmon parr in tanks (Scientific Reports, 2025). https://www.nature.com/articles/s41598-025-90118-9 — يُكيّف DeepLabCut لتقدير وضعية يرقات سلمون الأطلسي في أحواض تجريبية لمراقبة الرفاه/التوزّع المكاني.
- DeepLabCut: markerless pose estimation of user-defined body parts with deep learning (Mathis et al., Nature Neuroscience, 2018). https://www.nature.com/articles/s41593-018-0209-y — يحقّق DeepLabCut تتبّعًا بمستوى بشري بتصنيف نحو ٢٠٠ إطار فقط، يدعم نقاطًا مفصلية معرّفة من المستخدم، ويتتبّع الوضعية عبر مقاطع طويلة.
- COCO Keypoint Evaluation (cocodataset.github.io source). https://github.com/cocodataset/cocodataset.github.io/blob/master/dataset/keypoints-eval.htm — صيغة OKS وسيغما لكل نقطة مشتقّة من الانحراف المعياري لتصنيفات البشر نسبةً إلى حجم الجسم؛ محسوبة من ٥٬٠٠٠ صورة مصنَّفة بتكرار؛ العينان ضيّقتان، الوركان/الكاحلان فضفاضان؛ v=0/1/2.
- Object Keypoint Similarity in Keypoint Detection — LearnOpenCV. https://learnopencv.com/object-keypoint-similarity/ — OKS مقياس الوضعية المعياري في COCO، نظير قائم على المسافة لـ IoU؛ ثابت كل نقطة يعكس تباين المصنّفين (العينان ضيّقتان، المعصم/المرفق أفضفض).
- Keypoint Annotation — Definition & Training Data (Claru). https://claru.ai/glossary/keypoint-annotation — يستخدم ضبط جودة النقاط المفصلية اتفاق متعدّد المصنّفين عبر متوسط مسافة البكسل وعتبات التسامح؛ انخفاض الاتفاق لكل نقطة يشير إلى أدلّة غامضة لا لوم المصنّفين؛ النقاط على مراكز المفاصل.
- ViTPose — How to use the best Pose Estimation Model (Supervisely). https://supervisely.com/blog/vitpose-state-of-the-art-pose-estimation-model-in-supervisely/ — ViTPose نموذج من الأعلى للأسفل يحتاج كاشف أشخاص خارجيًا (مثل YOLO) لتزويد المربّعات، ثم يقدّر النقاط لكل قصاصة؛ يستطيع التصنيف المسبق لهياكل الوضعية ليصحّحها البشر.
- YOLOv7 Pose vs MediaPipe in Human Pose Estimation — LearnOpenCV. https://learnopencv.com/yolov7-pose-vs-mediapipe-in-human-pose-estimation/ — يكشف YOLO-pose الأشخاص ويستخرج نقاط COCO الـ١٧ في مرور أمامي واحد (المربّع + النقاط مُتنبَّأ بهما معًا).
- Data Annotation Pricing — Label Your Data. https://labelyourdata.com/pricing — معدّل تصنيف النقاط المفصلية المنشور يبدأ من ٠٫٠١٥ دولار لكل جسم (المربّع المحيط ٠٫٠٢ دولار).